
1. Introduction to Generative Artificial Intelligenceh2
Trong những năm gần đây, Machine learning (ML) đã mở rộng nhanh chóng phát triển trong lĩnh vực công nghệ thông tin, và hiện nay một bước tiến mới đang được định hình với công nghệ gọi là Generative AI - trí tuệ nhân tạo tạo sinh
-
Generative AI là gì
Generative AI là một nhánh của AI có khả năng tạo ra nội dung mới, như văn bản, hình ảnh, âm nhạc, video, và thậm chí là hội thoại. Thay vì chỉ dựa vào dữ liệu do con người cung cấp, Generative AI sử dụng các mô hình nền tảng (foundation models) đã được huấn luyện trước với lượng dữ liệu khổng lồ để tạo ra nội dung theo yêu cầu.
Ví dụ: bạn có thể nhập một vài dòng mô tả, và AI sẽ viết hẳn một đoạn mã, một bài blog, hay một câu chuyện dựa theo mô tả đó.
-
Generative AI khác gì so với các AI truyền thống ?
AI truyền thống Generative AI Thực hiện một tác vụ cụ thể dựa trên dữ liệu huấn luyện Có thể thực hiện nhiều tác vụ khác nhau Cần dữ liệu gắn nhãn rõ ràng Được huấn luyện từ dữ liệu tổng quát lớn Dự đoán hoặc phân loại (như phân tích cảm xúc, phân loại hình ảnh…) Tạo ra nội dung mới dựa trên lời nhắc (prompt) -
Prompting Engineering là gì?
Prompt Engineering là quá trình thiết kế và tối ưu hóa các câu lệnh hoặc lời nhắc (prompts) nhằm dẫn dắt mô hình AI sinh ra nội dung phù hợp. Điều này có thể bao gồm:
- Chọn từ khóa chính xác
- Cung cấp ngữ cảnh đầy đủ
- Đưa ví dụ rõ ràng
- Định hình lại cách đặt câu hỏi để gợi ý đúng hướng
Mục tiêu là giúp mô hình AI hiểu và phản hồi theo cách bạn muốn – nhanh chóng và chính xác.
Cách Prompt Engineering hoạt động
- Bắt đầu bằng một prompt – ví dụ: “Where is Japan located?”
- Mô hình xử lý và tạo ra phản hồi (gọi là inference) – “Japan is located in the northwest Pacific Ocean.”
- Kết quả được hiển thị và bạn có thể chọn giữ nguyên, chỉnh sửa, hoặc viết lại prompt để cải thiện kết quả.
Quan trọng: Không phải lúc nào kết quả cũng đúng ý – bạn có thể cần chỉnh lại lời nhắc hoặc đưa thêm ví dụ minh họa để mô hình hiểu rõ hơn.
-
Foundation model types
Khi xây dựng ứng dụng sử dụng Generative AI, việc chọn đúng loại foundation model (mô hình nền tảng) là yếu tố cực kỳ quan trọng để đạt hiệu quả cao nhất. Vậy có những loại mô hình nào, và chúng hoạt động ra sao?
Hiện nay có 3 loại foundation model phổ biến
-
Text to text - Từ văn bản sinh ra văn bản
Text-to-text foundation models được thiết kế để xử lý ngôn ngữ tự nhiên (NLP), đây cũng là loại mô hình được sử dụng phổ biến và rộng rãi nhất bởi các nhóm nghiên cứu startup và các công ty quy mô lớn.
Chức năng:
- Tóm tắt nội dung
- Trả lời câu hỏi
- Viết nội dung sáng tạo
- Hoàm thành câu trả lời.
Bạn nhập: “Summarize the benefits of cloud computing”, mô hình sẽ trả lại một đoạn tóm tắt súc tích và rõ ràng. Đây chính là nguyên lý hoạt động của các chatbot như ChatGPT.
-
Text-to-Embedding - Hiểu và so sáng nội dung văn bản.
Text-to-embeddings models không sinh ra văn bản mới mà chuyển văn bản thành dạng “embedding” – một đại diện số học mà máy tính có thể hiểu và so sánh.
Chức năng:
- Tìm kiếm thông minh
- So sánh mức độ liên quan giữa các đoạn văn bản
- Kết nối truy vấn người dùng với dữ liệu đã được lập chỉ mục
Ví dụ:
Khi bạn gõ vào thanh tìm kiếm của Amazon: “wireless noise cancelling headphones”, mô hình sẽ không chỉ tìm đúng từ khóa, mà còn hiểu ý định và trả về kết quả phù hợp hơn với nhu cầu của bạn.
-
Multimodal – Xử Lý Đa Dạng Định Dạng
Multimodal foundation models có thể xử lý và tạo ra nhiều định dạng khác nhau, như văn bản và hình ảnh.
Chức năng:
- Tạo ảnh từ văn bản
- Phân tích hình ảnh và mô tả bằng lời
- Kết hợp dữ liệu từ nhiều nguồn (văn bản, hình ảnh, âm thanh…)
Ví dụ:
Bạn nhập: “a futuristic city in the mountains at sunset”, mô hình như Stable Diffusion sẽ tạo ra một hình ảnh hoàn toàn mới dựa trên mô tả đó.
-
-
Generative AI industry use cases
2. Introduction to Large Language Modelsh2
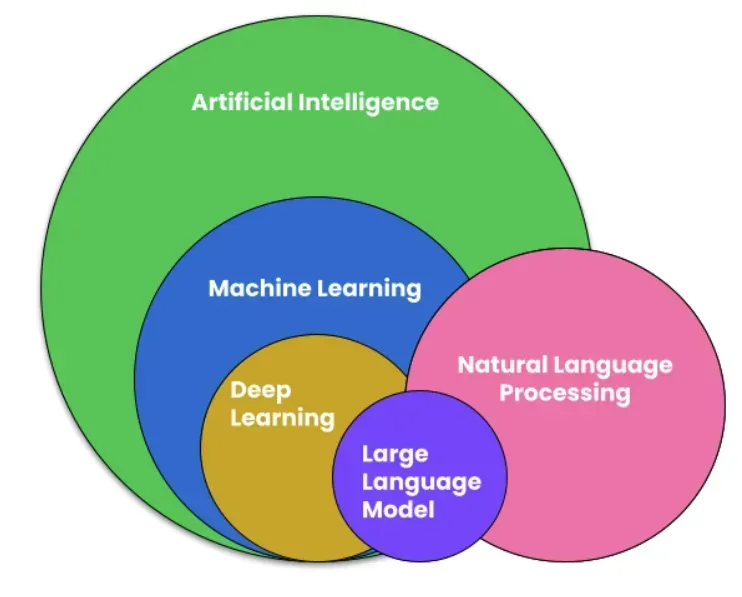
- LLM (Large Language Model) là một mô hình học sâu quy mô lớn, được huấn luyện trước trên khối dữ liệu khổng lồ.
- “Large”: Các mô hình LLM cần có khối lượng lớn dữ liệu và tài nguyên để huấn luyện (số lượng tham số cũng lớn).
- “Language”: Dữ liệu chính là Văn bản, thường lấy từ Internet, Wiki, và các kho dữ liệu lớn
- “Model” là hệ thống học từ dữ liệu để phát hiện mẫu và quy luật, không cần lập trình cụ thể.
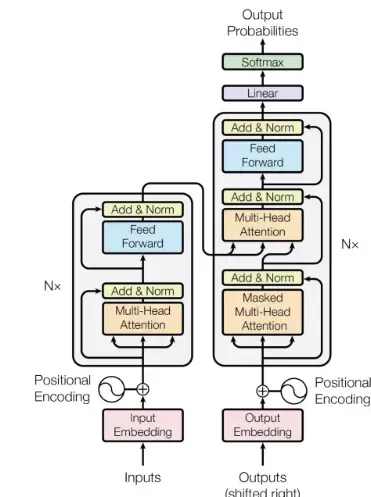
- Dựa vào kiến trúc của Transformer, gồm:
- Encoder và Decoder
- Cơ chế self-attention để hiểu mối quan hệ giữa các từ và cụm từ
Transformer có gì đặc biệt ?
-
Xử lí toàn bộ chuỗi văn bản song song, không truần tự như RNN → giúp mô hình huấn luyện nhanh hơn trên GPU.
-
Hỗ trợ mô hình rất lớn (hàng trăm tỷ tham số).
-
Có thể tự học (self-learning) để hiểu được ngữ pháp, ngôn ngữ kiến thức cơ bản.
Đặc điểm Self-Attention Multi-Head Attention Mục tiêu chính Hiểu mối quan hệ giữa các từ Hiểu nhiều mối quan hệ cùng lúc từ nhiều góc nhìn khác nhau Cách hoạt động Một mạng attention duy nhất Nhiều mạng attention chạy song song, rồi kết hợp lại Ưu điểm Nắm bắt được ngữ cảnh trong câu Tăng chiều sâu hiểu biết, biểu diễn phong phú hơn Ví dụ đời thường Lắng nghe từng người trong nhóm nói Vừa nghe, vừa để ý cảm xúc, chủ đề, thái độ của những người xung quanh
Một số LLM nổi bật:

2.1. Các mốc phát triển của Language Modelsh3
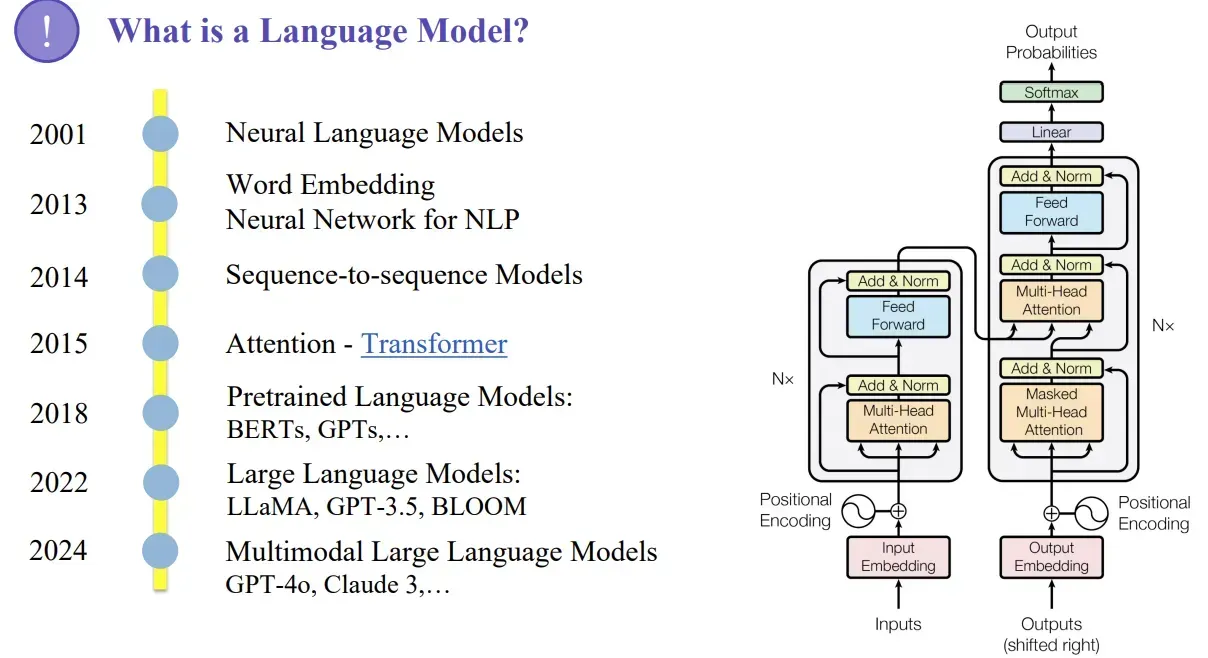
Không giống như mạng nơ ron hồi tiếp (RNN) xử lý dữ liệu theo tuần tự, Transformer có thể xử lý toàn bộ chuỗi đầu vào cùng lúc (song song). Nhờ đó, các nhà nghiên cứu khoa học dữ liệu có thể tận dụng được GPU để huấn luyện mô hình (LLMs) một cách nhanh chóng và hiệu quả.
Kiến trúc Transformer (ra đời năm 2015) sử dụng các thành phần chính:
- Multi-head attention (gồm nhiều self-attention xếp chồng lên nhau)
- Positional enconding (Mã hóa vị trí của từng từ trong câu)
- Feed-forward layers (các lớp xử lý tuyển tính)
- Add & Norm (Chuẩn hóa giá trị đầu vào sau mỗi bước)
- Masked attention (chỉ định vị trí mô hình được “chú ý trong huấn luyện)
Chính thiết kế thông minh và có thể mở rộng này đã cho phép các mô hình Transformer phát triển với quy mô rất lớn — thường chứa hàng trăm tỷ tham số, và được huấn luyện trên lượng dữ liệu khổng lồ như:
- Common Crawl: hơn 50 tỷ trang web
- Wikipedia: khoảng 57 triệu bài viết
Nhờ vào đó, các mô hình Transformer đã trở thành nền tảng của các mô hình hiện đại nhất như BERT, GPT, LLaMA, Claude… và mới đây là các mô hình đa phương thức như GPT-4o có thể xử lý cả văn bản, mã, hình ảnh và âm thanh.
2.2. How do large language models work?h3
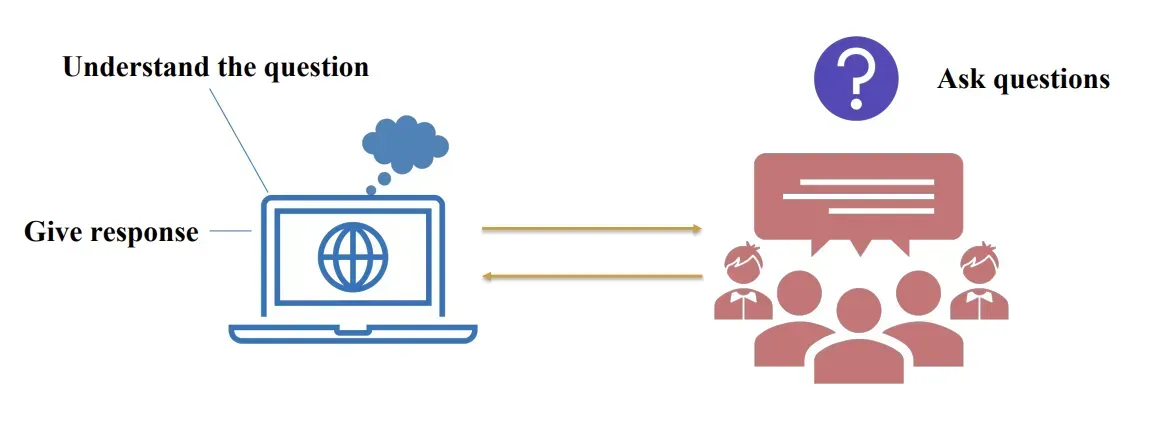
Mô hình lớn (LLMs) hoạt động dựa trên quy trình tương tác Hỏi - đáp giữa con người và máy tính:
- Người dùng đặt câu hỏi:
- Câu hỏi được nhập bằng ngôn ngữ tự nhiên.
- Mô hình hiểu câu hỏi:
- Sử dụng Word embeddings để nắm bắt ý nghĩa của các từ.
- Dùng kiến thức Transfomer để hiểu được ngữ cảnh và ý nghĩa trong toàn bộ câu hỏi.
- Mô hình đưa ra phản hồi
- Dựa trên kiến thức đã học, mô hình tạo ra câu trả lời phù hợp bằng ngôn ngữ tự nhiên.
2.3. Ứng dụng thực tế của LLMsh3
3. Pre-training GPTh2
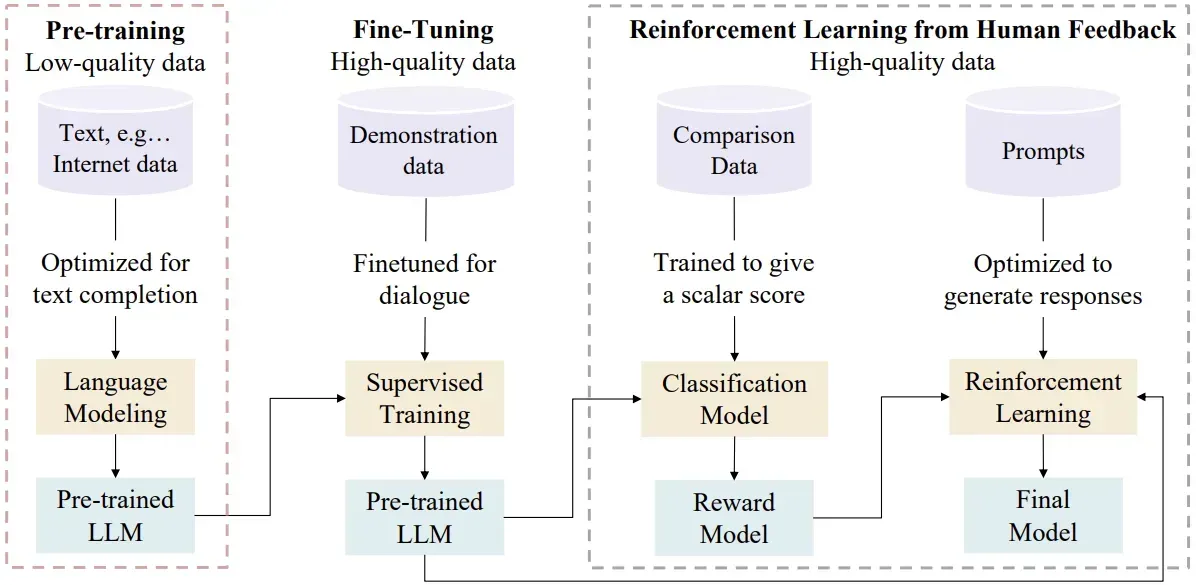
3.1. Pre-training là gì?h3
Mục tiêu:
-
Dạy mô hình học được các quy luật của các ngôn ngữ tự nhiên chung như:
- Ngữ pháp
- Cấu trúc câu
- Kiến thức nền (facts)
-
Dữ liệu sử dụng
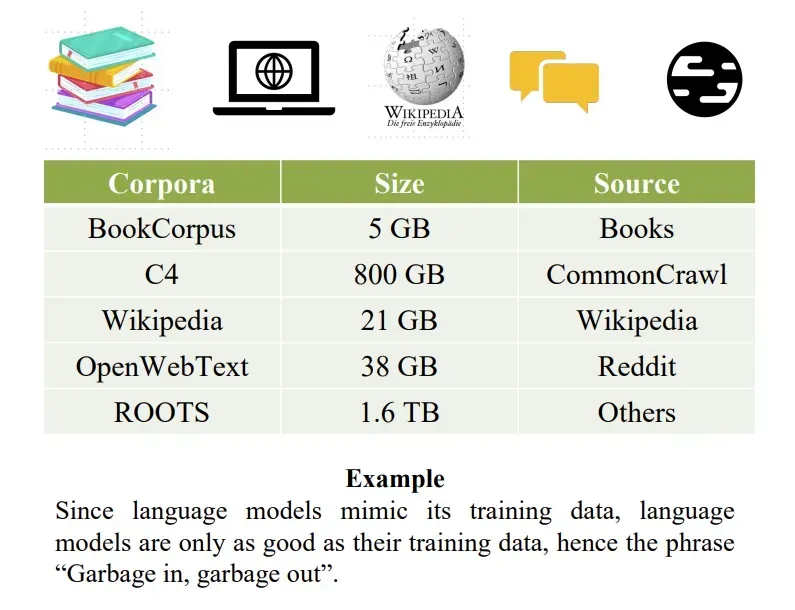
-
Dữ liệu văn bản không gán nhãn và đa dạng như website, paper, book, wiki, …
-
Cách hoạt động:
- Dựa trên kiến trúc Transformer
- Sử dụng kỹ thuật
- Next-word prediction (dự đoán từ tiếp theo)
- Masked Language Modeling (dự đoán từ bị ẩn)
-
Kết quả đầu ra:
- Mô hình có khả năng dự đoán từ tiếp theo cho hợp lý hoặc hoàn thành câu văn bản tự nhiên.
-
Được gọi là Pre-trained LLM - Mô hình ngôn ngữ lớn đã huấn luyện sơ bộ, sẵn sàng cho fine-tuning.
3.2. Fine-tuningh3
Mục tiêu:
- Điều chỉnh mô hình GPT đã được huấn luyện sơ bộ để thực hiện tốt các tác vụ cụ thể
- Ví dụ: trả lời hội thoại, dịch thuật, phân loại văn bản,…
Dữ liệu sử dụng:
- Dữ liệu chất lượng cao, đã được gán nhãn rõ ràng
- N-shot learning techniques:
- Zero-shot: Cho phép mô hình giải quyết nhiệm vụ cụ thể mà chưa từng được huấn luyện trực tiếp, chỉ dựa vào hiểu biết tổng quát về ngôn ngữ và thế giới. ****
- Few-shot: Tinh chỉnh mô hình GPT để thực hiện tốt một nhiệm vụ với chỉ vài ví dụ gán nhãn.
- Multi-shot learning: Tinh chỉnh mô hình cho các tác vụ cụ thể với nhiều ví dụ hơn, từ đó cải thiện khả năng tổng quát hóa và độ chính xác.
Kết quả:
- Mô hình trở nên chính xác hơn với nhiệm vụ cụ thể
- Nhưng vẫn có thể bị ảnh hưởng bởi nhiễu trong dữ liệu đầu vào (ví dụ: thông tin sai lệch từ các diễn đàn)
3.3. RLHF - Reinforcement learning from human feedbackh3
Mục tiêu:
-
Vượt qua hạn chế của fine-tuning truyền thống (nhưng vấn có thể bị ảnh hưởng bởi nhiễu trong dữ liệu đầu vào)
-
Đưa các yếu tố đánh giá chất lượng phản hồi từ con người vào quá trình huấn luyện
-
Giúp mô hình hiểu “phản hồi tốt” là như thế nào thay vì chỉ học được từ dữ liệu có sẵn
-
Quy trình 3 bước RLHF
- Tạo phản hồi → Mô hình sinh ra nhiều câu trả lời cho cùng một prompt
- Con người đánh giá → Chuyên gia xếp hạng các câu trả lời theo tiêu chí: độ chính xác, tự nhiên, hợp ngữ cảnh
- Huấn luyện mô hình thưởng (Reward Model) → Dựa trên xếp hạng để đánh giá chất lượng đầu ra áp dụng Reinforcement Learning để tinh chỉnh và cập nhật Final Model
| Giai đoạn | Dữ liệu | Kỹ thuật chính | Kết quả đầu ra |
|---|---|---|---|
| Pre-training | Văn bản thô, Internet | Language Modeling | Hiểu ngôn ngữ tổng quát |
| Fine-tuning | Dữ liệu gán nhãn | Supervised Learning | Tối ưu cho nhiệm vụ cụ thể |
| RLHF | Phản hồi từ con người | Reinforcement Learning | Mô hình phù hợp, tự nhiên, chính xác |
Pre-training GPT-2:
Để hiểu rõ về các quá trình huấn luyện mô hình, trong bài này chúng ta sẽ tập trung phân tích nội dung ở bước đầu tiên Pre-training.
Code Pre-training: Google Colab
Code Fine-tunning: Google Colab
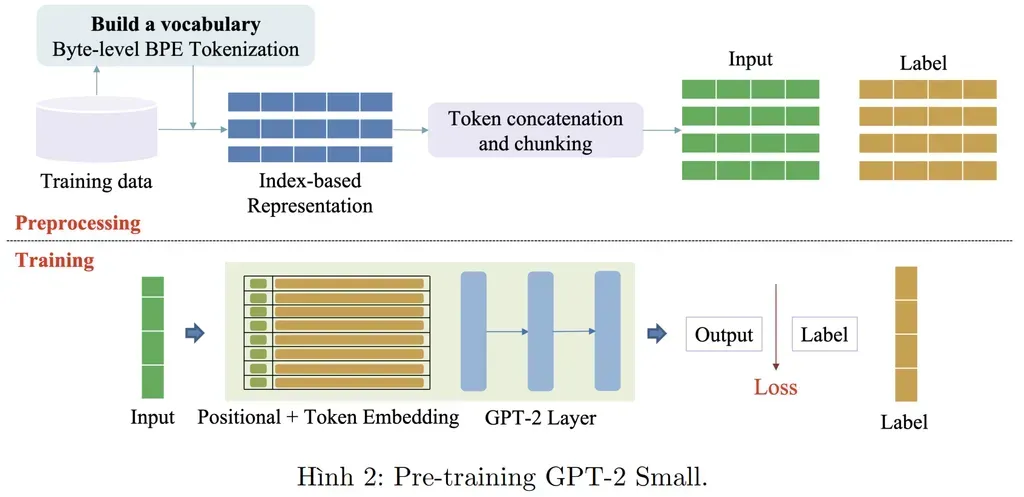
3.4. Pre-training GPT-2h3
a. Preprocessing
from datasets import load_dataset
ds = load_dataset("datablations/c4-filter-small", split="train") # Datasetds = ds.select_columns(["text"])ds = ds.train_test_split(test_size=0.1) # DatasetDictb. Tokenization
Trong bài này sẽ sử dụng Byte level BPE Tokenization để mã hóa văn bản thành các token. BPE là một phương pháp nén dữ liệu, giúp giảm số lượng từ cần xử lý và tăng hiệu quả của mô hình.
Byte Representation – Mã hóa theo Byte
Mỗi ký tự trong chuỗi văn bản (bao gồm chữ, số, dấu cách, emoji…) được chuyển thành mã số nguyên (byte) theo bảng mã UTF-8.
Chi tiết về mã hóa theo Byte
-
Mỗi ký tự được mã hóa thành một hoặc nhiều byte.
-
Ví dụ: Ký tự “A” được mã hóa thành byte
65, ký tự “B” thành byte66,…
Văn bản: “I am going to sing”
→ Byte hóa:
[73, 32, 97, 109, 32, 103, 111, 105, 110, 103, 32, 116, 111, 32, 115, 105, 110, 103]
Đây là dữ liệu đầu vào thô để bắt đầu tokenization.
Ưu điểm byte-level:
- Không phụ thuộc ngôn ngữ (đa ngữ, có dấu, đặc biệt, emoji…)
- Dễ xây dựng từ điển ban đầu (chỉ 256 ký tự byte)
Byte-Pair Encoding – Gộp theo tần suất
BPE tiến hành tìm các cặp byte xuất hiện thường xuyên và gộp chúng lại để tạo thành các subword tokens.
[105, 110, 103] → “ing”
Các byte có tần suất xuất hiện lớn → được gộp thành token riêng. Quá trình này lặp lại nhiều lần, từ từ xây dựng bộ từ vựng tối ưu.
from tokenizers import Tokenizerfrom tokenizers.models import BPE # Byte Pair encoderfrom tokenizers.trainers import BpeTrainerfrom tokenizers.pre_tokenizers import ByteLevelfrom tokenizers.normalizers import NFKCfrom tokenizers.decoders import ByteLevel as ByteLevelDecoder
# Initialize BPE tokenizertokenizer = Tokenizer(BPE())tokenizer.pre_tokenizer = ByteLevel() # chuyển từng từ về dạng bytr như UTCtokenizer.normalizer = NFKC() # Normalize kiểu ví dụ như Hóa với Hoá hai từ này là mộttokenizer.decoder = ByteLevelDecoder()
"""<s> để đánh dấu đầu vào,<pad> lấp đầy,</s> kết thúc câu,<unk> tại vì trong vocab chỉ chứa được tối đa vocabsize từ vậy nên các từ vượt quá sẽ sẽ được đánh dấu bằng token này,<mask> che một từ trong câu cho mô hình đoán lại từ đó"""
trainer = BpeTrainer( vocab_size=50257, special_tokens=["<s>", "<pad>", "</s>", "<unk>", "<mask>"])
# tran tìm vocab từ tập dữ liệutokenizer.train_from_iterator(ds["train"]["text"], trainer)tokenizer.save("gpt_tokenizer.json")from transformers import PreTrainedTokenizerFast
tokenizer = PreTrainedTokenizerFast(tokenizer_file="gpt_tokenizer.json")tokenizer.add_special_tokens({ "bos_token": "<s>", "eos_token": "</s>", "unk_token": "<unk>", "pad_token": "<pad>", "mask_token": "<mask>",})
tokenizer.save_pretrained("gpt-tokenizer")c. Training
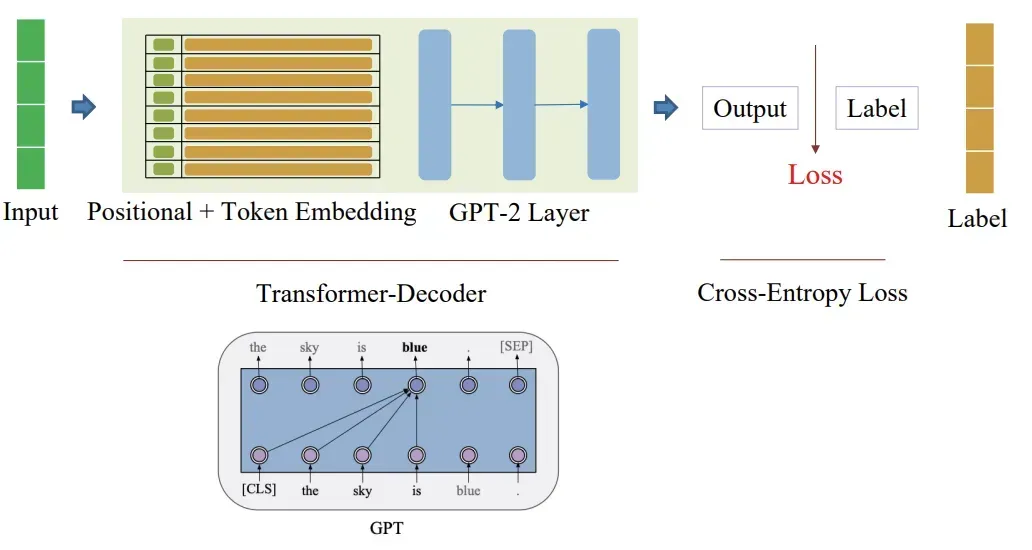
from transformers import GPT2Config, GPT2LMHeadModel
config = GPT2Config( vocab_size=tokenizer.vocab_size, n_positions=512, # chiều dài của embedding vị trí n_ctx=512, # số token GPT-2 có thể nhìn thấy tối đa để dự đoán tiếp theo. n_embd=512, # số embeding n_layer=6, # số layer n_head=8, # số head bos_token_id=tokenizer.bos_token_id, eos_token_id=tokenizer.eos_token_id)model = GPT2LMHeadModel(config)# công cụ để xem log thôiimport wandbwandb.init( project="gpt2-pretraining", name="c4-en-small")from transformers import Trainer, TrainingArguments, DataCollatorForLanguageModeling
"""Nó xử lý và chuẩn hóa batch dữ liệu đầu vào cho mô hình, ví dụ:Tự động pad các chuỗi có độ dài khác nhauTạo ra labels cho huấn luyện(Nếu mlm=True) sẽ mặt nạ các token đầu vào (masking) như trong BERT"""data_collator = DataCollatorForLanguageModeling( tokenizer=tokenizer, mlm=False)
training_args = TrainingArguments( output_dir="gpt-small-c4", # 📁 Thư mục lưu model checkpoint logging_dir="logs", # 📁 Thư mục lưu log TensorBoard per_device_train_batch_size=16, # 🧠 Batch size mỗi GPU cho huấn luyện per_device_eval_batch_size=16, # 🧪 Batch size mỗi GPU cho đánh giá num_train_epochs=20, # 🔁 Số epoch huấn luyện eval_strategy="steps", # 🧪 Đánh giá sau mỗi số bước (không phải theo epoch) save_strategy="steps", # 💾 Lưu model theo từng bước logging_strategy="steps", # 📊 Ghi log theo từng bước eval_steps=1000, # 📐 Đánh giá mỗi 1000 bước save_steps=1000, # 💾 Lưu model mỗi 1000 bước logging_steps=1000, # 📈 Ghi log mỗi 1000 bước save_total_limit=1, # 💾 Chỉ giữ lại 1 checkpoint mới nhất metric_for_best_model="eval_loss", # 🥇 Chọn mô hình tốt nhất theo eval loss greater_is_better=False, # 🔻 Loss càng nhỏ càng tốt load_best_model_at_end=True, # ✅ Sau khi huấn luyện, load model tốt nhất fp16=True # 🚀 Dùng mixed precision (float16) nếu GPU hỗ trợ)
trainer = Trainer( model=model, # 🔧 Mô hình GPT-2 bạn định huấn luyện args=training_args, # ⚙️ Đối tượng cấu hình ở trên train_dataset=lm_ds["train"], # 🧾 Dataset huấn luyện eval_dataset=lm_ds["test"], # 📊 Dataset đánh giá processing_class=tokenizer, # ⚠️ Dòng này bị sai → nên là `tokenizer=tokenizer` data_collator=data_collator # 📦 Gom dữ liệu đầu vào (xử lý padding, labels,...))
trainer.train()trainer.save_model("gpt2-pretrained")3.5. Inferenceh3

from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "thainq107/gpt-small-c4"
model = AutoModelForCausalLM.from_pretrained(model_name)tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "I go to"inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
output = model.generate( **inputs, max_new_tokens=100, do_sample=True, pad_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(output[0], skip_special_tokens=True))Tính score
import math
# Shift for labels (causal LM setting: predict token t+1 from token t)# -> cách mà huggingface làm như nãy có đề cập
labels = output[:, 1:].clone()inputs = output[:, :-1].clone()
with torch.no_grad(): outputs = model(inputs) logits = outputs.logits
print(logits.shape)
# Compute log softmax over vocabularylog_probs = torch.nn.functional.log_softmax(logits, dim=-1)print(log_probs.shape)
# Gather log-probabilities corresponding to the labelsselected_log_probs = log_probs.gather(2, labels.unsqueeze(-1)).squeeze(-1)
# Sum negative log probs → total NLLnll = -selected_log_probs.sum().item()num_tokens = labels.numel()perplexity = math.exp(nll / num_tokens)perplexity