2. RAG Prompting with LangChain
RAG Prompting with LangChain
Documents_RAG-Prompting-and-LangChain
1. Introductionh1
Các mô hình ngôn ngữ lớn (LLMs) là các mô hình AI được huấn luyện trên một tập dữ liệu văn bản rất lớn. Việc huấn luyện trên một lượng dữ liệu khổng lồ này giúp chúng có khả năng thực hiện nhiều tác vụ xử lý ngôn ngữ tự nhiên (NLP) với độ chính xác cao, chẳng hạn như sinh văn bản, dịch thuật, tóm tắt và trả lời câu hỏi.
LLMs thươngd dược train trên một hoặc nhiều dữ liệu khác nhau để đưa ra 1 foundation model giúp xử lý được rất nhiều task khác nhau
-
Overview về LLMs được đưa vào sản phẩm.
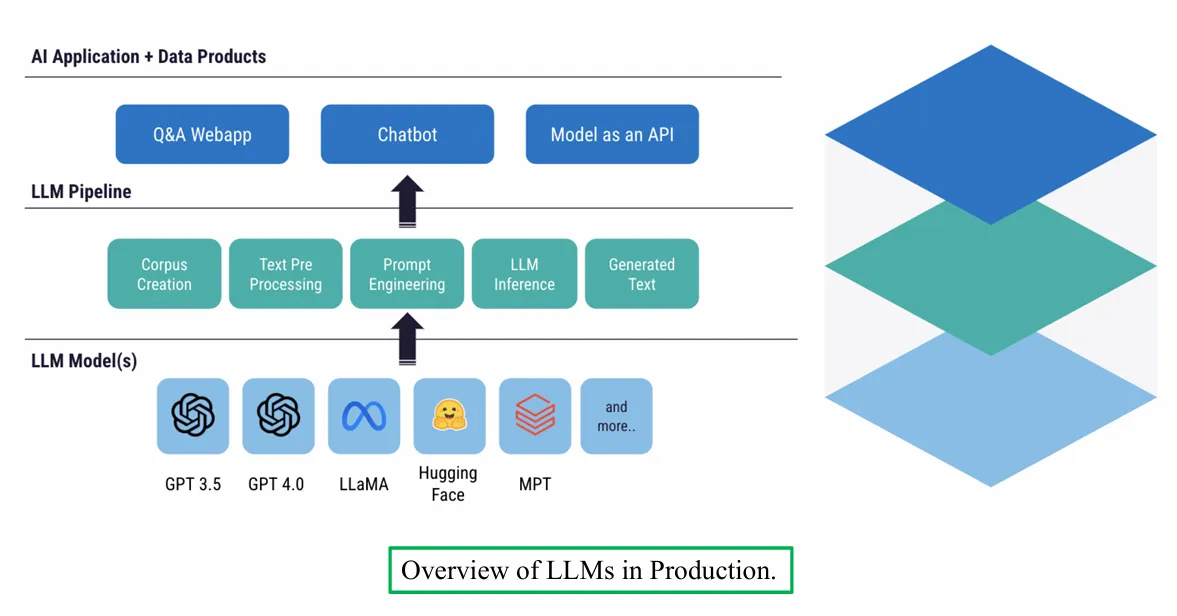
Hình ảnh cung cấp cái nhìn tổng quan về việc triển khai mô hình ngôn ngữ lớn (LLMs) trong sản xuất, với ba tầng chính:
- Ứng dụng AI và Sản phẩm Dữ liệu: Bao gồm các ứng dụng như Q&A/Webapp, Chatbot, và Model as an API.
- Quy trình LLM (LLM Pipeline): Gồm các bước: Tạo dữ liệu (Corpus Creation), Tiền xử lý văn bản (Text Pre-processing), Kỹ thuật gợi ý (Prompt Engineering), Suy luận LLM (LLM Inference), và Tạo văn bản (Generated Text).
- Mô hình LLM (LLM Model(s)): Liệt kê các mô hình như GPT 3.5, GPT 4.0, LLaMA, Hugging Face, MPT và các mô hình khác.
-
LLMs Aplications
2. LangChainh1
LangChain là một framework cho phát triển ứng dụng LLMs một cách mạnh mẽ. LangChains đơn gian hóa các stage của một vòng đời ứng dụng LLMs bao gồm: Phát triển (development, productionization, deployment).
-
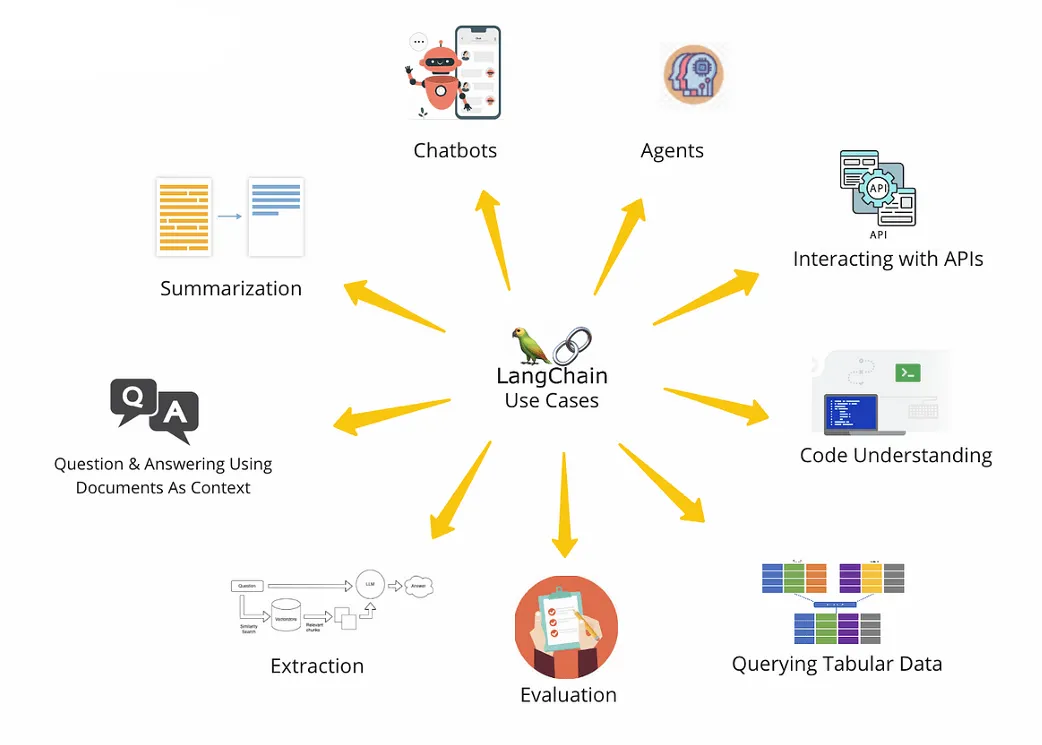
Langchain Usecase
-
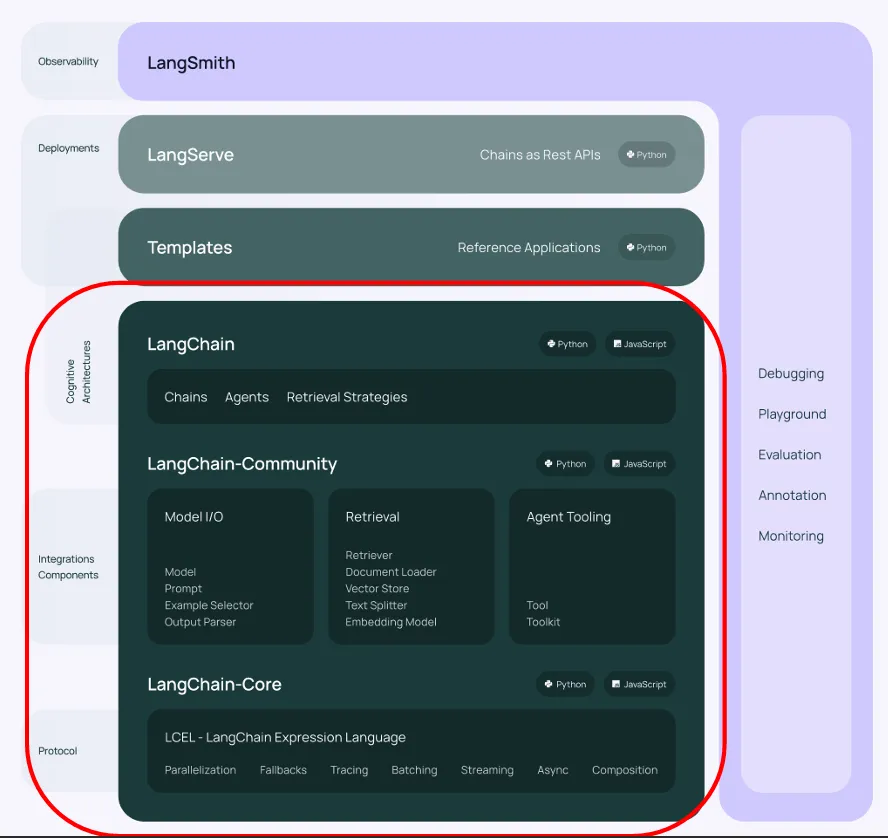
Cấu trúc của LangChain

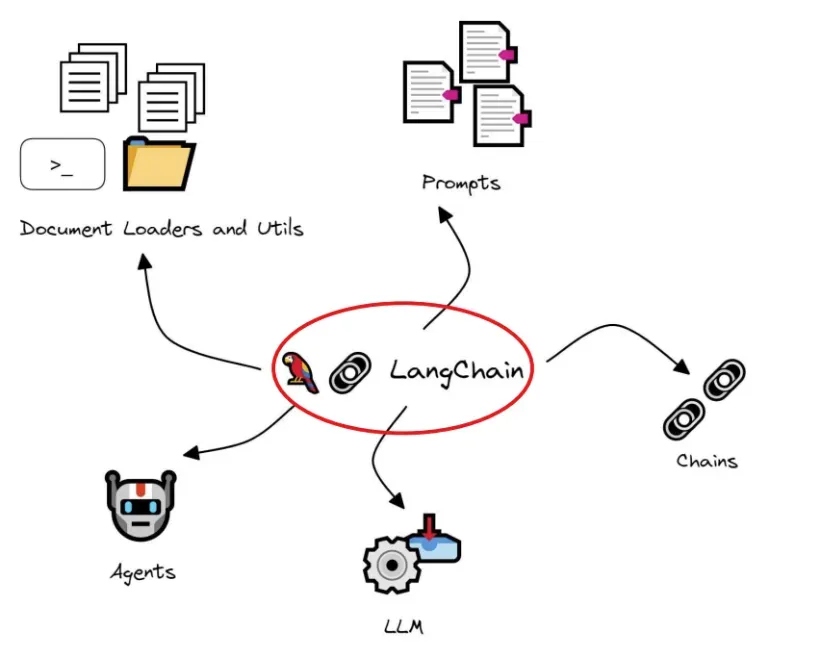
Overview LangChain
-
LangChain (Development)
Model I/O - Giao tiếp với mô hình ngôn ngữ lớn (LLM)
- Model: Trong langchain hỗ trợ rất nhiều mô hình mã nguồn mở từ huggingface, olama, …. hoặc sử dụng API của các mô hình truy vấn công khi như ChatGPT, Claude, Gemini,… Thay vì phải viết mã phúc tạp, chỉ cần đơn giản gọi API.
- Prompt: Cấu trúc định dạng truy vấn đầu vào của LLMs. Hỗ trợ tạo mẫu câu hỏi theo ngữ cảnh chatbot, few-shot learning hoặc hướng dẫn cụ thể. Có thể tái sử dụng nhiều ứng dụng và mô hình khác nhau.
- Ouput Parsers: Dùng để phân tích và định dạng lại phản hồi từ mô hình theo cấu trúc mong muốn như JSON, bảng, text, chuẩn hóa.
Retrieval – Tăng cường tri thức mô hình (RAG – Retrieval-Augmented Generation)
- Document Loaders: Công cụ nạp dữ liệu từ file, PDF, trang web, database…
- Text Splitters: Tách văn bản lớn thành đoạn nhỏ để dễ xử lý và lập chỉ mục.
- Embedding Models: Chuyển đổi các đoạn văn bản thành vector biểu diễn ngữ nghĩa.
- Vector Stores: Cơ sở dữ liệu lưu trữ và tìm kiếm vector, dùng trong truy vấn ngữ nghĩa (FAISS, Chroma, Pinecone…).
- Retrievers: Cơ chế tìm kiếm đoạn nội dung phù hợp nhất dựa trên truy vấn người dùng – là lõi trong các hệ thống RAG.
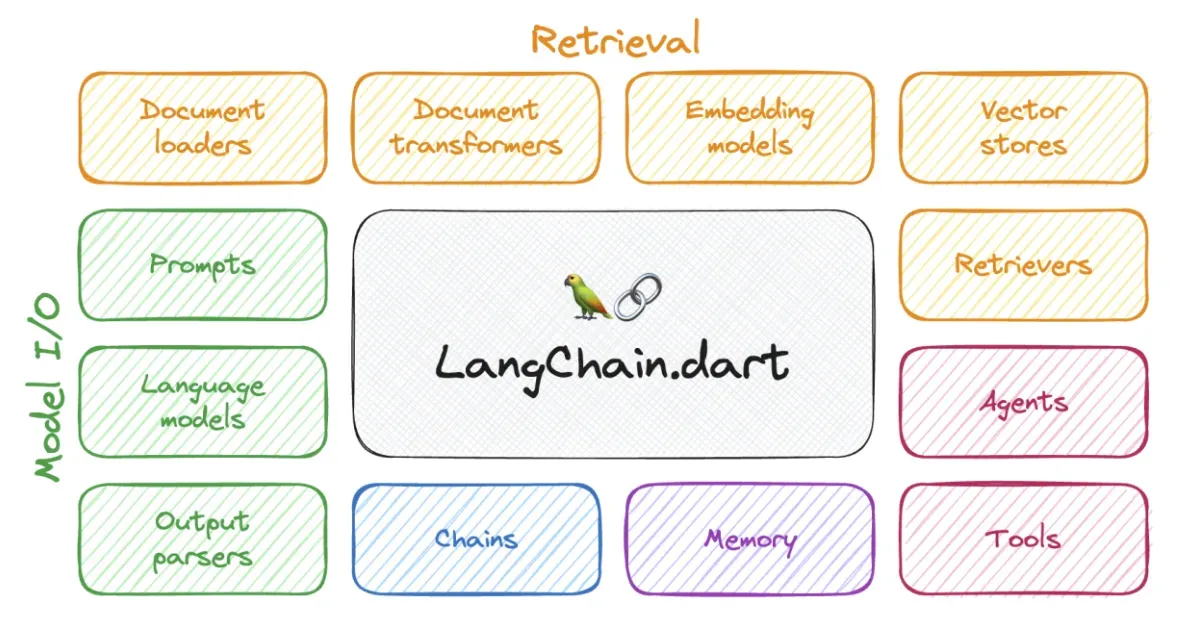
Composition – Kết hợp thành ứng dụng hoàn chỉnh
- Chains: Chuỗi các hành động liên tiếp (mô hình, prompt, parser, retriever…). Cho phép xây dựng luồng xử lý phức tạp như RetrievalQA, Sequential Chains.
- Agents: Một loại đặc biệt của chain, nơi mô hình quyết định thứ tự và công cụ cần dùng để đạt được mục tiêu. Người dùng cung cấp truy vấn, công cụ sẵn có và mô hình sẽ xây dựng chiến lược hành động phù hợp.
- Tools: Giao diện giúp agent hoặc chain tương tác với hệ thống bên ngoài (API, tìm kiếm, cơ sở dữ liệu, Python REPL…).
Memory – Trí nhớ hội thoại
- Hỗ trợ ghi nhớ nội dung trong các tương tác trước đó.
- Có thể là bộ nhớ đơn giản (nhớ lượt trò chuyện gần nhất) hoặc phức tạp (phân tích lịch sử hội thoại để phản hồi phù hợp hơn).
Callbacks – Theo dõi & giám sát hoạt động
- Các hook chèn vào trong chuỗi xử lý LangChain.
- Cho phép ghi log, giám sát, stream thông tin, theo dõi thời điểm thực thi, lỗi phát sinh…
LangChain Expression Language (LCEL) – Ngôn ngữ biểu đạt mô-đun
Một cách khai báo (declarative) để tổ chức và chạy các thành phần (model, prompt, retriever, chain…) theo chuẩn Runnable.
- Hỗ trợ các tính năng mạnh:
- Parallelization (xử lý song song)
- Fallbacks (thử nhiều phương án)
- Streaming (truy vấn thời gian thực)
- Tracing (ghi vết chi tiết)
- Composition (kết hợp dễ dàng)
Cấu trúc thư viện LangChain theo tầng
langchain-core: Khái niệm nền tảng, chuẩn giao tiếp Runnable, LCEL…langchain: Các thành phần tổng quát như chains, agents, strategies…langchain-community: Tích hợp cụ thể với mô hình, vector store, công cụ truy xuất…
-
LangServe
Để triển khai ứng dụng langchain như một RESTAPI.
- Tích hợp FASTAPI giúp tăng hiệu suất và dễ mỡ rộng.
- Sử dụng Pydantic để tự động kiểm tra và sinh tài liệu API
- Các endpoint mặc định như:
/invoke,/batch,/stream/stream_log,/stream_events(giám sát nội bộ)
- Có sẵn giao diện web /playground để thử nghiệm tương tác API.
- Cung cấp SDK cho Python/JS giúp gọi API như gọi hàm local.
👉 LangServe là cầu nối từ ý tưởng đến sản phẩm thực tế, giúp bạn chuẩn hóa quy trình triển khai ứng dụng LLM.
-
LangSmith
Dùng LangSmith để giám sát, đánh giá và tối ưu hiệu suất ứng dụng AI trong môi trường sản xuất.
- Tracing chi tiết: Theo dõi mọi bước trong quy trình thực thi, bao gồm độ trễ, chi phí token…
- Evaluation (Đánh giá): Kiểm tra chất lượng đầu ra bằng tiêu chí tùy chỉnh hoặc LLM làm giám khảo.
- Monitoring: Theo dõi chỉ số kinh doanh & kỹ thuật như lỗi, tốc độ phản hồi, chi phí…
- Debug trực quan: Giúp phát hiện và sửa lỗi nhanh chóng.
- Prompt Playground: Thử nghiệm và so sánh nhiều phiên bản prompt.
- Dataset & Human Feedback: Tạo bộ dữ liệu kiểm thử và thu thập đánh giá từ con người.
LangSmith có thể hoạt động độc lập hoặc tích hợp mượt mà với LangChain / LangGraph, hỗ trợ cả self-host.
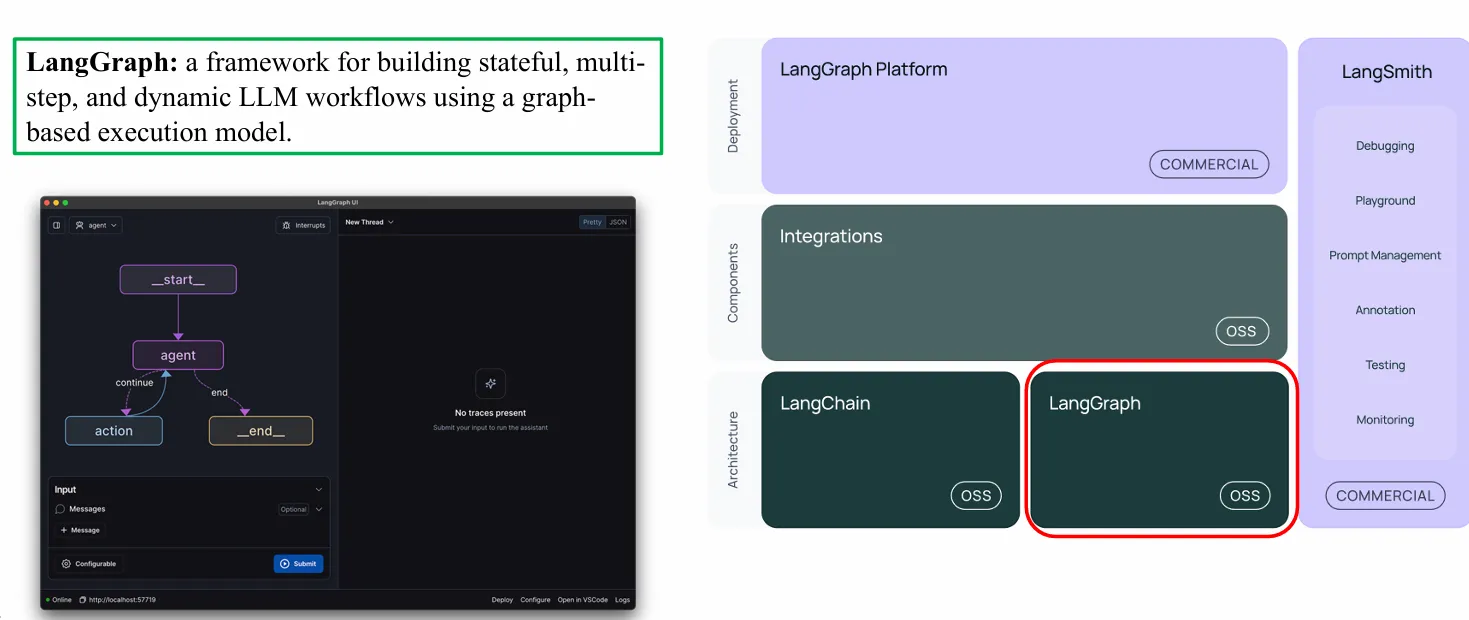
LangGraph là một framework mã nguồn mở (OSS) cho phép xây dựng các quy trình làm việc với LLM theo mô hình đồ thị (graph-based execution model). Nó hỗ trợ:
- Trạng thái (stateful): lưu giữ trạng thái trong suốt quá trình.
- Nhiều bước (multi-step): thực hiện chuỗi tác vụ phức tạp.
- Động (dynamic): luồng thực thi có thể thay đổi tùy vào kết quả trung gian.
-
3. RAG with LangChainh1
3.1. Use LLM in LangChainh2
LangChain cung cấp một giao diện thống nhất để tương tác với nhiều loại mô hình ngôn ngữ lớn (LLM), bao gồm mô hình độc quyền từ 2 module chính là GPT từ OpenAI và mô hình mã nguồn mở từ Hugging Face.
-
OpenAI models

- Sử dụng lớp
ChatOpenAItừ thư việnlangchain_openaiđể định nghĩa mô hình GPT. - Mỗi lời gọi đến mô hình sẽ gửi truy vấn đến OpenAI API và nhận kết quả phản hồi.
- Cần API key để hoạt động, tuy nhiên trong khóa học DataCamp, bạn sẽ được cung cấp sẵn key giả lập.
- Để gửi prompt, chỉ cần dùng phương thức
.invoke()với chuỗi văn bản. - Có thể cấu hình thêm các tham số như:
temperature: điều chỉnh độ sáng tạo (tạo sinh các kết quả giữa các câu hỏi giống nhau sẽ có phần khác nhau càng tiến về 1 sẽ càng khác khoảng giá trị củatemperaturelà [0;1]max_completion_tokens: giới hạn số lượng token phản hồi
- Sử dụng lớp
-
Hugging Face models
-
Using
BitsAndBytesConfig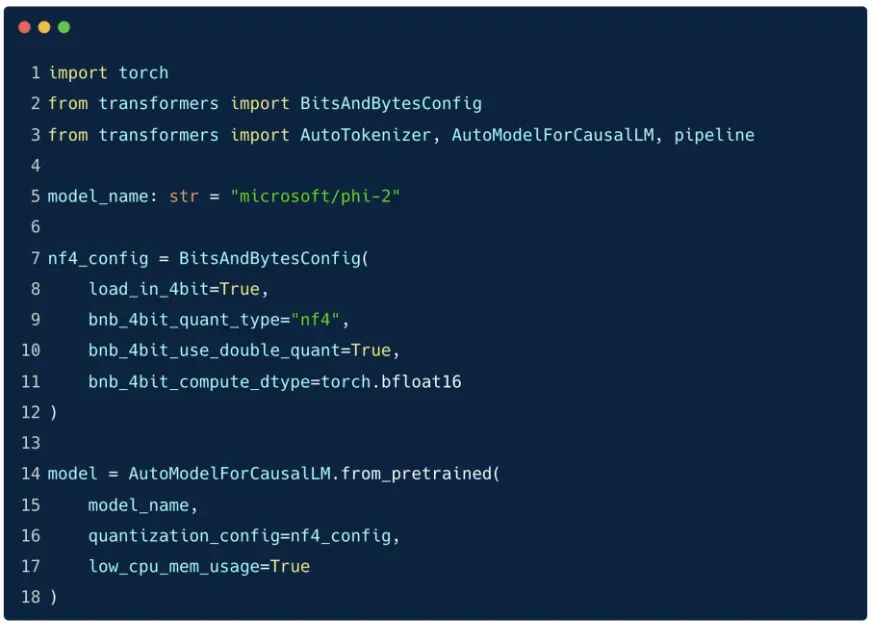
BitsAndBytes giúp giảm dung lượng VRAM khi tải mô hình LLM bằng cách nén (quantize) trọng số xuống 8-bit hoặc 4-bit mà vẫn giữ hiệu năng ổn định.
Lợi ích chính:
- Tiết kiệm bộ nhớ GPU: Giảm mạnh dung lượng so với FP32 hoặc FP16 → chạy mô hình lớn (ví dụ LLaMA-13B) ngay cả trên GPU 16GB.
- Chạy trên phần cứng phổ thông: Dễ dàng dùng mô hình nhiều tỷ tham số trên laptop cá nhân, Google Colab, v.v.
- Tích hợp tốt với Hugging Face Transformers.
- Duy trì độ chính xác cao nhờ kỹ thuật:
- NF4 (Normal Float 4) – tối ưu cho phân phối trọng số mô hình.
- Double Quantization – nén thêm cả hằng số dùng trong quantize.
- Mixed-precision compute – lưu bằng 4-bit, tính bằng BF16/FP16 để không mất chính xác.
💻 Các bước trong mã nguồn:h3
-
Cấu hình
BitsAndBytesConfigThiết lập các tùy chọn nạp mô hình 4-bit:
bnb_4bit_quant_type = "nf4"bnb_4bit_use_double_quant = Truebnb_4bit_compute_dtype = torch.bfloat16
-
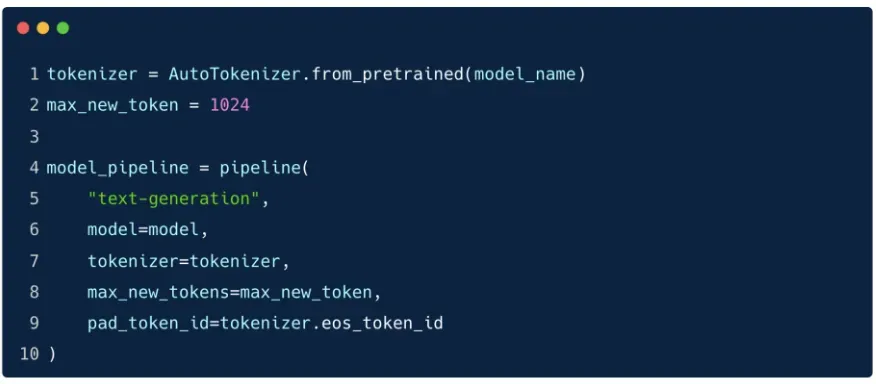
Load mô hình
Dùng
AutoModelForCausalLM.from_pretrained(...), truyền thêm:quantization_config = nf4_configlow_cpu_mem_usage = True(tiết kiệm RAM)
-
Tạo tokenizer và pipeline Hugging Face
- Dùng
AutoTokenizer.from_pretrained(...) - Thiết lập pipeline
text-generationvới tokenizer + model
- Dùng
-
Tích hợp với LangChain thông qua
HuggingFacePipeline-
Gán pipeline vừa tạo vào
HuggingFacePipeline -
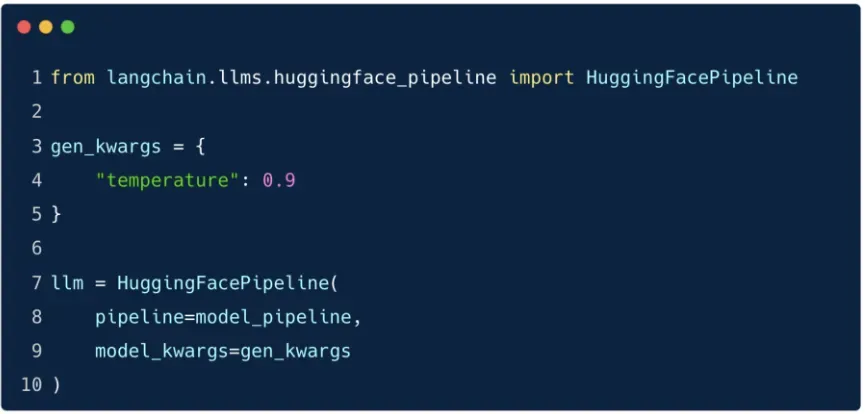
Cấu hình thêm
temperature(ví dụ:0.9) thông quamodel_kwargs:gen_kwargs = { "temperature": 0.9 }
-
🔎 Ghi chú:
temperaturecàng cao → phản hồi đa dạng, sáng tạo hơn nhưng cũng dễ “lệch chủ đề”.temperaturethấp → phản hồi ổn định, thực tế hơn nhưng kém linh hoạt.
-
Not use
BitsAndBytesConfig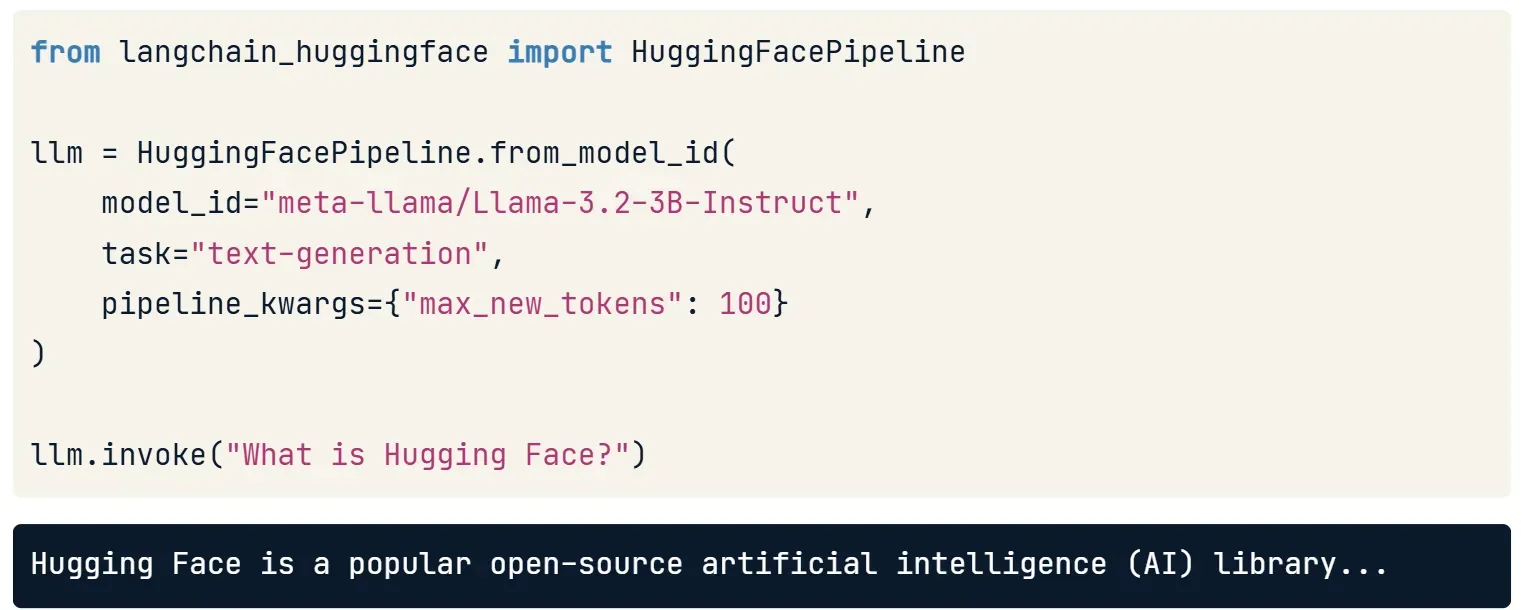
- Dùng lớp
HuggingFacePipeline.from_model_id()để tải mô hình cho nhiệm vụ cụ thể (ví dụ: sinh văn bản). - Mô hình có thể được tải về và chạy cục bộ, không cần gọi API từ xa.
- Gửi prompt cũng tương tự: dùng
.invoke()như với mô hình GPT.
- Dùng lớp
-
3.1.1. Prompt Templatesh3

Trong LangChain, PromptTemplate là thành phần cốt lõi dùng để tạo mẫu lời nhắc (prompt) cho các mô hình ngôn ngữ.
Chúng hoạt động như công thức sẵn có (predefined recipes) giúp định dạng đầu vào một cách linh hoạt, có thể tái sử dụng.
Cấu trúc của một Prompt Template có thể bao gồm:
- Instructions: Hướng dẫn mô hình phải làm gì.
- Few-shot examples: Ví dụ mẫu để mô hình bắt chước.
- Context & Questions: Thông tin bổ sung và câu hỏi liên quan tới tác vụ cụ thể.
Các loại Prompt Template trong LangChain
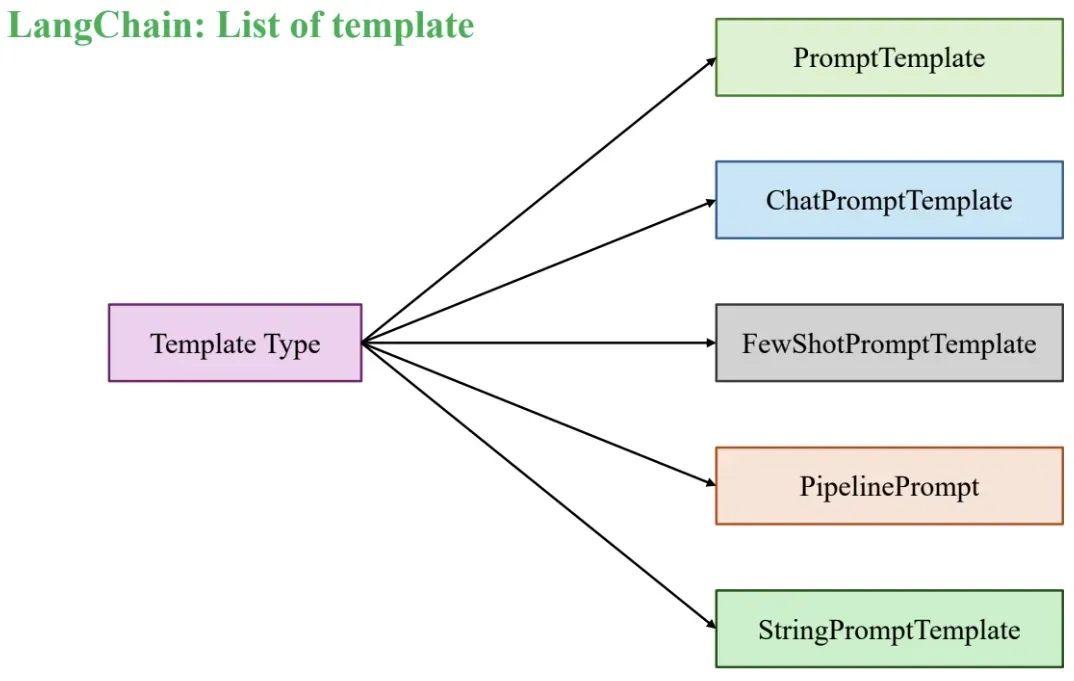
| Loại Template | Mô tả |
|---|---|
| PromptTemplate | Mẫu prompt đơn giản dạng chuỗi có thể chèn biến bằng {}. Phù hợp cho các task truyền thống với input đầu vào rõ ràng. |
| ChatPromptTemplate | Thiết kế dành riêng cho các mô hình chat (Chat Model). Hỗ trợ phân vai rõ ràng như: system, human, ai. |
| FewShotPromptTemplate | Dùng trong few-shot learning: kết hợp prompt chính với một loạt ví dụ mẫu để hướng dẫn mô hình. |
| PipelinePromptTemplate | Cho phép xây dựng prompt phức tạp bằng cách kết hợp nhiều prompt nhỏ thành một chuỗi xử lý logic (pipeline). |
| StringPromptTemplate | Hỗ trợ định nghĩa prompt dưới dạng chuỗi tùy chỉnh với khả năng lập trình logic để xử lý đầu vào phức tạp. |
-
PromptTemplate
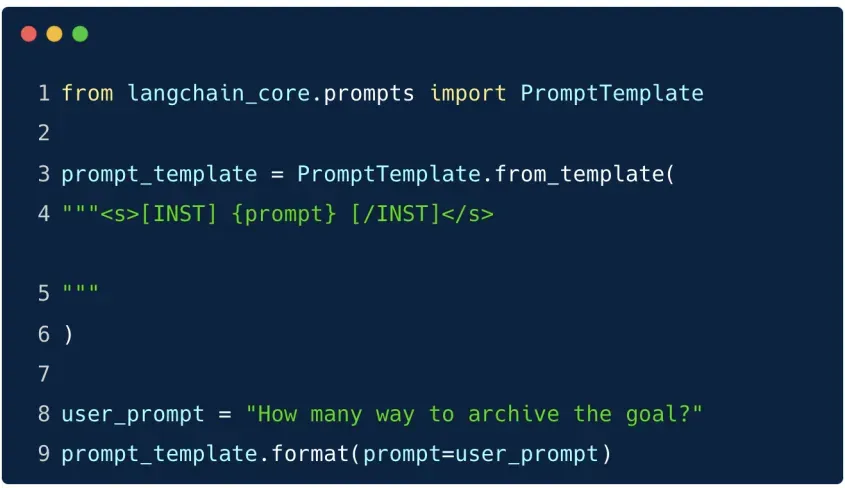
PromptTemplatelà lớp đơn giản nhất trong LangChain để xây dựng lời nhắc (prompt) dựa trên chuỗi văn bản có chèn biến động.- Đây là mẫu prompt cơ bản, cho phép chèn dữ liệu đầu vào vào các vị trí định sẵn bằng
{}. - Rất hữu ích khi bạn cần tạo lời nhắc linh hoạt, có thể tái sử dụng trong nhiều ngữ cảnh khác nhau.
Cách tạo PromptTemplate
-
Viết chuỗi văn bản với biến chèn động, ví dụ:
"Explain this concept simply and concisely: {concept}" -
Chuyển chuỗi đó thành template bằng phương thức
.from_template(). -
Chèn dữ liệu thực tế bằng
.invoke()với một dictionary, ví dụ:{"concept": "Prompting LLMs"}
- Đây là mẫu prompt cơ bản, cho phép chèn dữ liệu đầu vào vào các vị trí định sẵn bằng
-
ChatPromptTemplate
ChatPromptTemplatelà loại prompt được thiết kế riêng cho các mô hình hội thoại (chat-based LLMs) như GPT-4, Claude, Gemini…Loại prompt này hỗ trợ phân vai trong hội thoại, giúp mô hình hiểu được ngữ cảnh và hành vi mong muốn.
Các vai trò (Roles) được hỗ trợ:
system: Mô tả hành vi hoặc tính cách của mô hình (VD: “Bạn là một máy tính, chỉ trả lời bằng toán học.”)human: Tin nhắn từ người dùng (câu hỏi, yêu cầu…)ai: Câu trả lời mẫu từ AI
🔧 Cách sử dụng:
Dùng phương thức
from_messages()để tạo mộtChatPromptTemplatetừ danh sách các cặp(vai trò, nội dung). -
FewShotPromptTemplate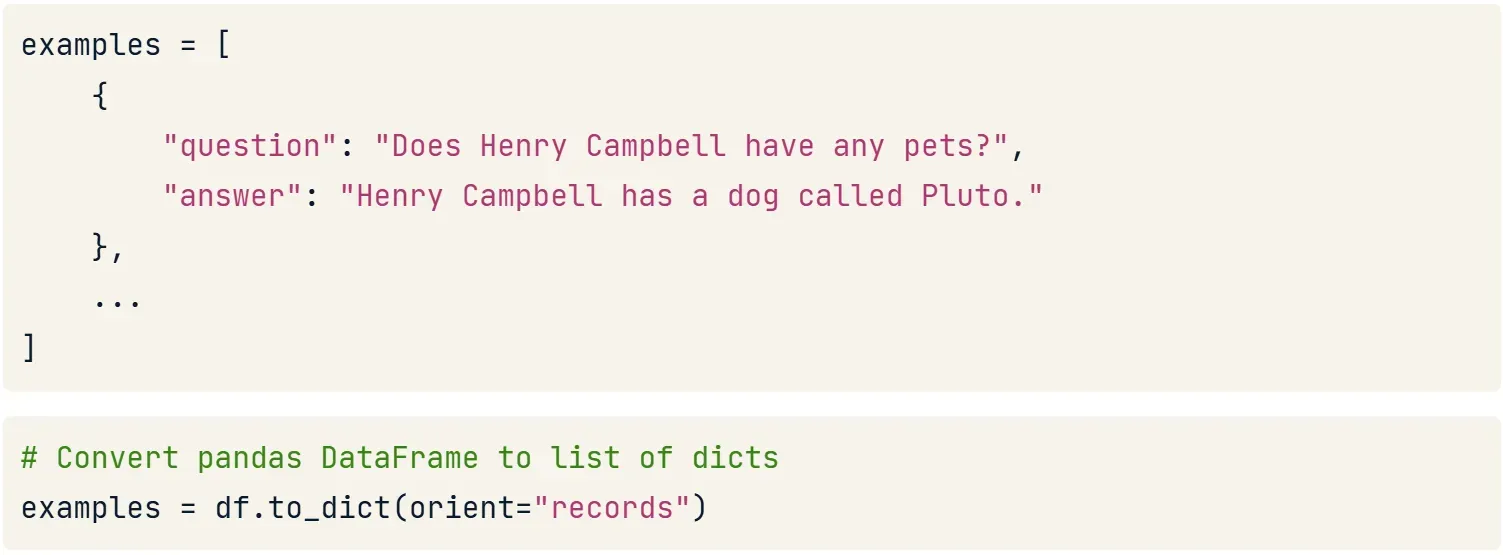


FewShotPromptTemplatelà một loại prompt cho phép đưa nhiều ví dụ mẫu (examples) vào lời nhắc (prompt), giúp mô hình học được cách trả lời trước khi xử lý câu hỏi mới.Phù hợp khi bạn muốn mô hình tổng quát hóa từ nhiều ví dụ có cấu trúc giống nhau — thay vì chỉ dựa vào một prompt đơn lẻ.
🔍 Vì sao cần dùng
FewShotPromptTemplate?- Các template như
PromptTemplatehayChatPromptTemplatechỉ hiệu quả với một ví dụ duy nhất. - Khi cần cung cấp nhiều ví dụ từ dữ liệu (dataset, DataFrame…),
FewShotPromptTemplatelà lựa chọn tối ưu. - Mô hình sẽ học từ các ví dụ trước để trả lời câu hỏi mới đúng định dạng và logic hơn.
Các bước chính:h3
- Tạo danh sách ví dụ (
examples):
examples = [{"question": "Does Henry Campbell have any pets?","answer": "Henry Campbell has a dog called Pluto."}]Đây là danh sách các ví dụ mẫu dạng câu hỏi-trả lời (có thể lấy từ DataFrame bằng .to_dict()).
- Định nghĩa định dạng của từng ví dụ (
example_prompt):
example_prompt = PromptTemplate.from_template("Question: {question}\n{answer}")Dòng này định nghĩa cách hiển thị mỗi ví dụ (trong danh sách
examples) trước khi đưa vàoFewShotPromptTemplate.
- Tạo
FewShotPromptTemplate:
prompt_template = FewShotPromptTemplate(examples=examples,example_prompt=example_prompt,suffix="Question: {input}",input_variables=["input"])Gộp nhiều ví dụ thành 1 prompt
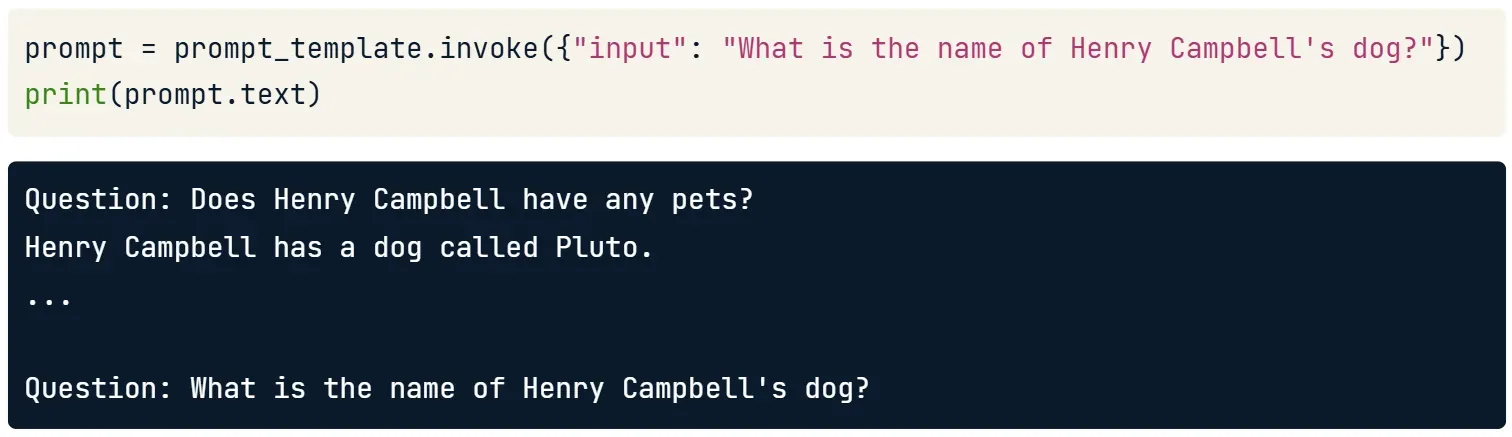
suffixlà phần prompt chứa câu hỏi mới của người dùnginputlà biến sẽ được chèn vàosuffix- Sử dụng template để hỏi câu mới:
prompt = prompt_template.invoke({"input": "What is the name of Henry Campbell's dog?"})print(prompt.text)Tự động ghép ví dụ mẫu và câu hỏi mới thành một prompt hoàn chỉnh gửi đến LLM
- Các template như
-
PipelinePromptTemplate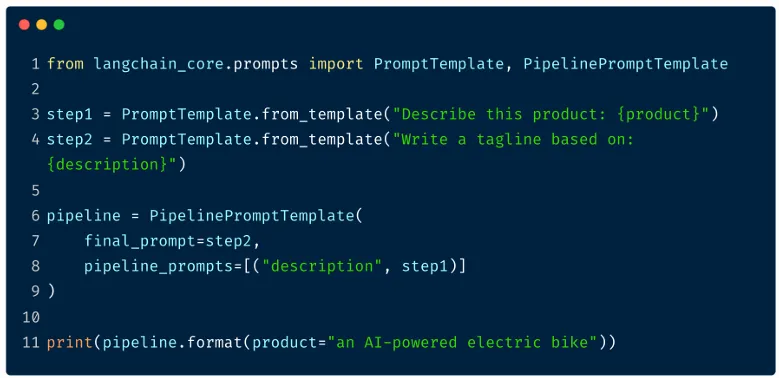
PipelinePromptTemplate: Cho phép chuỗi nhiều bước prompt lại với nhau bằng cách truyền kết quả trung gian làm biến đầu vào cho các bước tiếp theo. -
StringPromptTemplate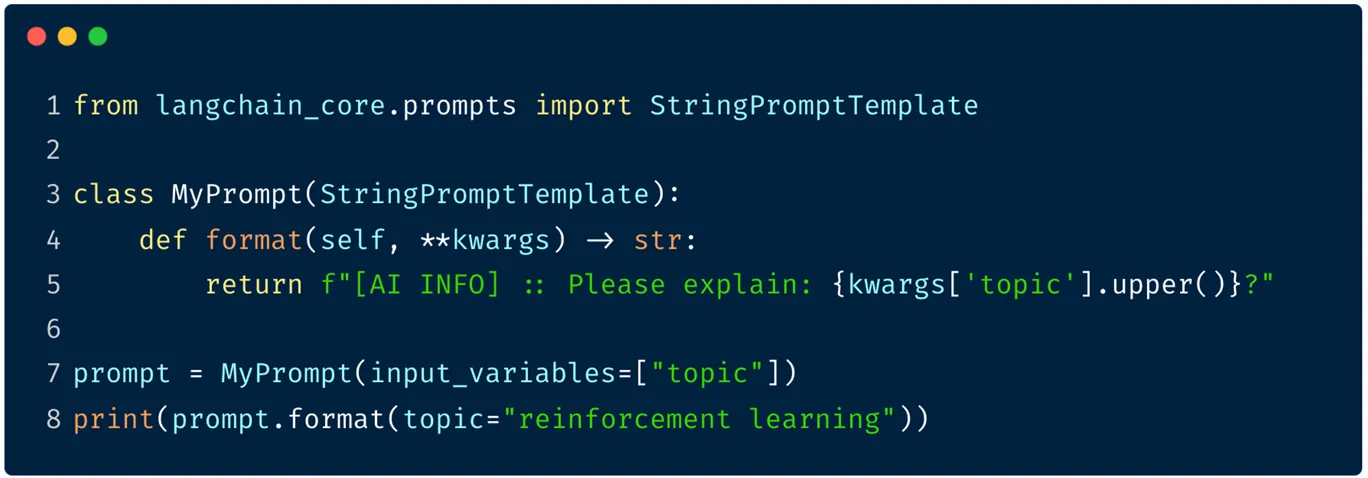
StringPromptTemplate là một lớp cơ sở (base class) dùng để tự định nghĩa logic tạo prompt động một cách linh hoạt. Nó cho phép bạn viết custom prompt logic bằng Python, vượt ra ngoài các mẫu định dạng {} thông thường.
3.1.2. Chainh3
Trong LangChain, Chain (chuỗi xử lý) là một cách tổ chức các bước xử lý nối tiếp nhau để hoàn thành một tác vụ, như trả lời câu hỏi, phân tích dữ liệu, hoặc sử dụng công cụ hỗ trợ.
Cấu trúc hoạt động:
- Một Chain có thể bao gồm:
- Mẫu câu hỏi (
PromptTemplate) - Mô hình ngôn ngữ (như GPT, Claude, LLaMA…)
- Các công cụ hoặc bước xử lý bổ sung (gọi API, tính toán, tra cứu tài liệu…)
- Mẫu câu hỏi (
- Dữ liệu đầu vào (câu hỏi người dùng) sẽ đi qua từng bước, mỗi bước xử lý xong sẽ chuyển tiếp sang bước tiếp theo.
Vì sao cần Chain?
- Giúp xử lý những tác vụ phức tạp bằng cách chia nhỏ thành từng phần.
- Kết nối linh hoạt nhiều mô-đun: mô hình, công cụ bên ngoài, bộ dữ liệu, v.v.
- Dễ bảo trì, thay đổi, nâng cấp vì cấu trúc rõ ràng và tách biệt.
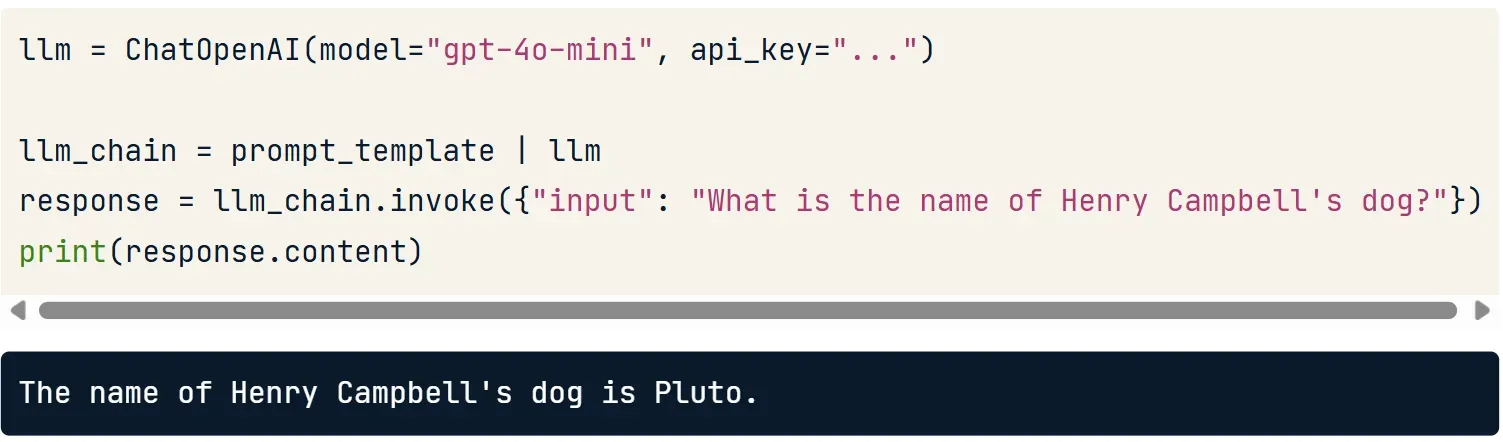
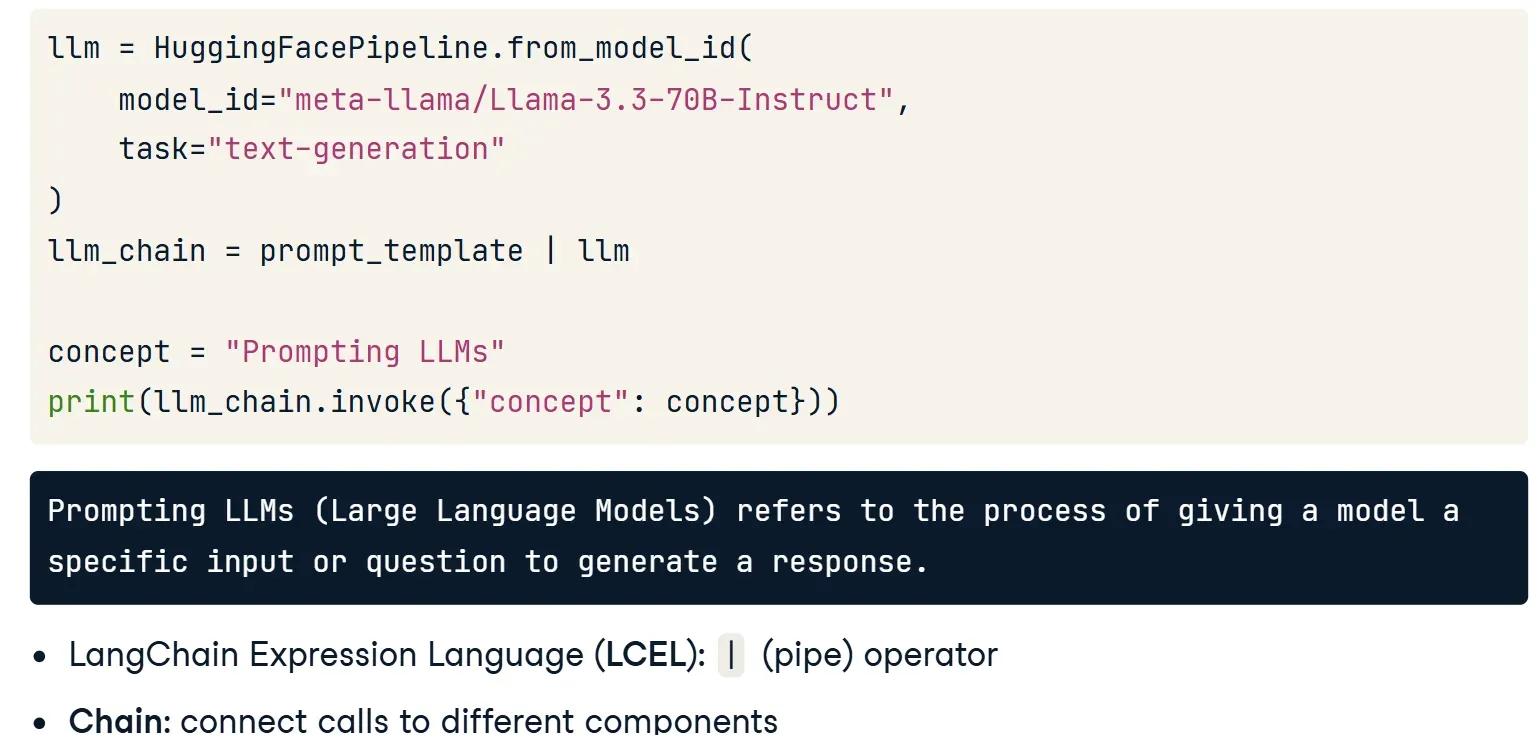
💡 Ví dụ đơn giản: LLMChain : Sử dụng chain để ghép nối từng thành phần bằng ký tự |
llm_chain = prompt_template | llmDòng này có nghĩa:
prompt_templatesẽ định dạng dữ liệu đầu vào- Sau đó kết quả được truyền tiếp qua
llmđể mô hình xử lý
Lưu ý quan trọng:
- Ký tự
|ở đây không phải là “hoặc” (OR), mà là toán tử kết nối (pipe) trong LangChain Expression Language (LCEL).
3.1.1. Parserh3
Khi bạn hỏi cùng một câu hỏi hai lần, mô hình có thể trả lời khác nhau cả nội dung và định dạng. Ví dụ: hỏi công thức món ăn, đôi khi mô hình bắt đầu bằng nguyên liệu, đôi khi là cách làm. Với con người, điều này có thể chấp nhận được. Nhưng khi bạn cần máy tính xử lý đầu ra tự động (ví dụ để đưa vào báo cáo), thì việc này sẽ gây lỗi.
Ví dụ trong công việc: Dùng LLM để tóm tắt Support Tickets hỗ trợ thành 3 mục:
- Vấn đề
- Nguyên nhân
- Cách giải quyết
Nhưng mô hình trả về với nhiều định dạng khác nhau như:
- Có khi là đoạn văn
- Có khi là danh sách gạch đầu dòng
- Có khi có tiêu đề Issue, có khi chỉ là Issue, hoặc không có gì cả
→ 🧨 Kết quả: logic xử lý lỗi, vì đầu ra không có cấu trúc nhất quán
Giải pháp: Output Parser
LangChain cung cấp các Output Parser để:
- Yêu cầu mô hình trả lời theo định dạng mong muốn
- Tự động phân tích đầu ra thành dữ liệu dễ xử lý (list, datetime, object…)
| 🧩 Parser | 🧾 Định dạng đầu ra | 📝 Mô tả |
|---|---|---|
CommaSeparatedListOutputParser | list[str] | Phân tách chuỗi bằng dấu phẩy → danh sách các chuỗi |
DatetimeOutputParser | datetime | Chuyển đổi chuỗi ngày giờ → đối tượng datetime của Python |
JsonOutputParser | dict / JSON string | Parse chuỗi JSON thành đối tượng Python (dict) |
PydanticOutputParser | Pydantic model (Python object) | Parse chuỗi văn bản thành object tuân theo model định nghĩa bằng Pydantic |
-
JSON Output Parser
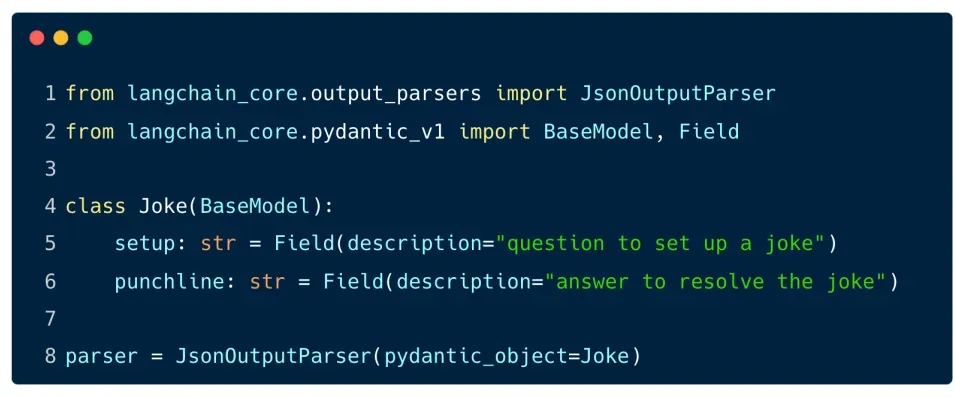

Cách hoạt động :
- Định nghĩa đối tượng Pydantic:
Để sử dụng
JsonOutputParser, bạn cần định nghĩa một lớp Pydantic để mô tả cấu trúc của đối tượng bạn muốn ánh xạ dữ liệu vào. Pydantic là một thư viện giúp định nghĩa các cấu trúc dữ liệu với các kiểu dữ liệu cụ thể, đồng thời kiểm tra và xác thực dữ liệu. - Sử dụng JsonOutputParser:
Sau khi định nghĩa lớp Pydantic, bạn có thể sử dụng
JsonOutputParserđể phân tích đầu ra của mô hình và chuyển đổi nó thành một đối tượng Pydantic.
Ở ví dụ trên
PromptTemplateđược dùng để tạo một prompt cho mô hình ngôn ngữ, trong đó có phần format instructions để yêu cầu mô hình trả về câu trả lời theo định dạng JSON.JsonOutputParsersẽ nhận đầu ra của mô hình và chuyển đổi nó thành đối tượngJoke, mà ở đó sẽ có hai thuộc tínhsetupvàpunchline.
- Định nghĩa đối tượng Pydantic:
Để sử dụng
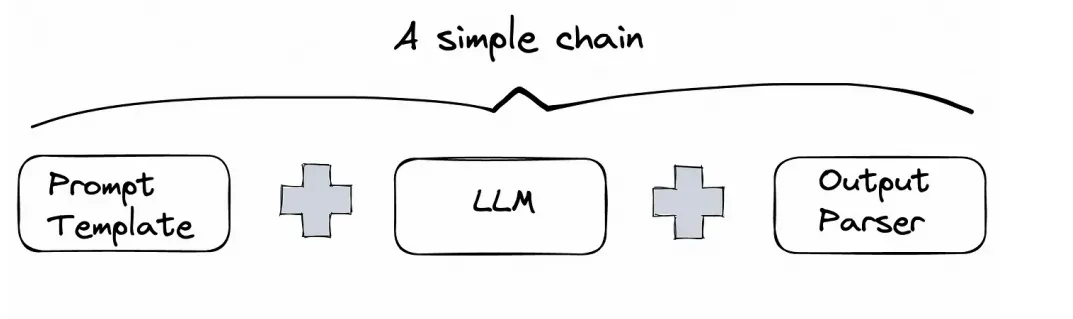
Giờ, ta kết hợp tất cả để tạo thành một chuỗi xử lý đơn giản như sau:
- Người dùng nhập điểm đến (ví dụ: “Paris”).
- Prompt đầu tiên (
destination_prompt) sinh ra gợi ý các hoạt động tại điểm đó. - Kết quả được
StrOutputParser()xử lý → dùng làm input cho Prompt thứ hai (activities_prompt). - Prompt thứ hai sinh ra một lịch trình 1 ngày từ 3 hoạt động gợi ý trước đó.
- Kết quả cuối cùng được parser xử lý và in ra.
3.2. Langchian-Communityh2
-
Document Loader
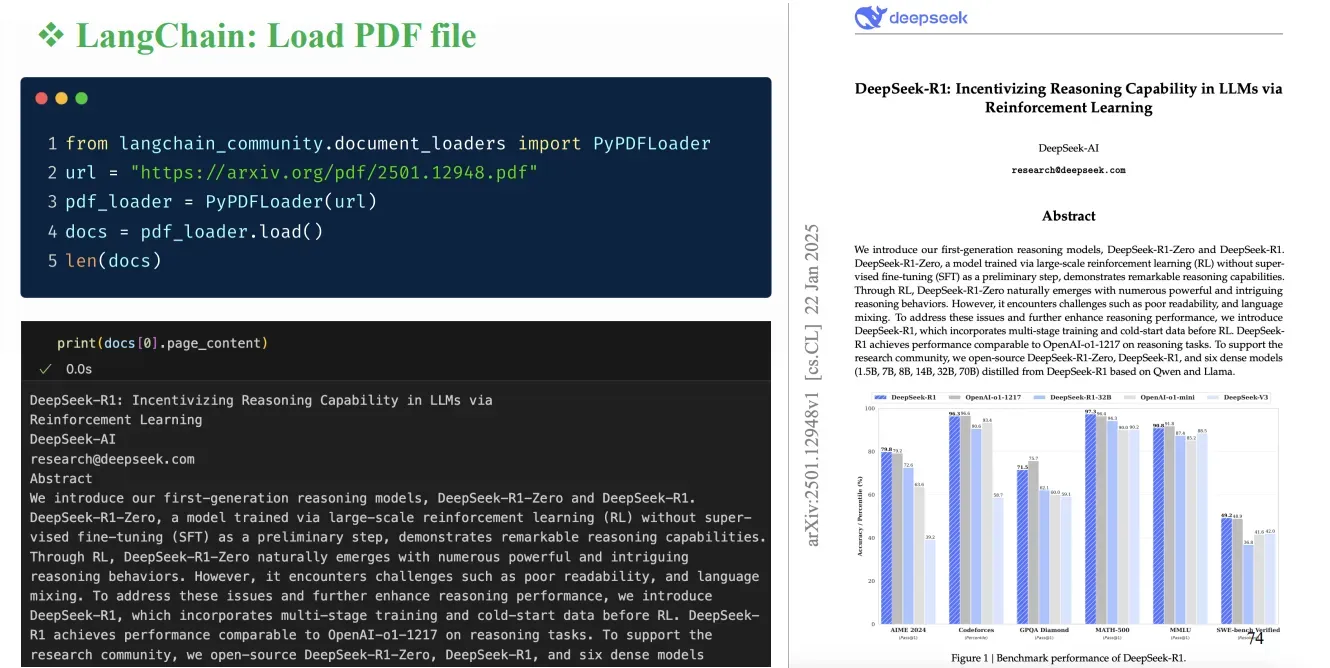


Trong nhiều ứng dụng LLM như RAG (Retrieval Augmented Generation), mô hình cần truy cập vào các tài liệu bên ngoài dữ liệu huấn luyện để:
- Trả lời câu hỏi từ dữ liệu nội bộ
- Cập nhật thông tin gần đây
- Tùy biến theo ngữ cảnh cụ thể (hệ thống, người dùng…)
Vì thế, Document Loaders đóng vai trò là “cửa ngõ” để đưa tài liệu từ nhiều nguồn khác nhau vào hệ thống LangChain.
-
🧰 Document Loader là gì?
Document Loaders là các lớp (class) trong LangChain được thiết kế để:
- Tải dữ liệu từ các tệp và nguồn bên ngoài
- Chuyển đổi tài liệu sang định dạng phù hợp để xử lý, tách đoạn (chunk), lập chỉ mục và tìm kiếm
-
🗂️ Các loại tài liệu được hỗ trợ:
https://python.langchain.com/docs/how_to/#document-loaders
Loại tệp thông dụng Loader tương ứng PDF PyPDFLoader,PDFMinerLoader, …CSV CSVLoaderHTML UnstructuredHTMLLoaderMarkdown UnstructuredMarkdownLoaderAudio/Transcript .wav,.mp3quaWhisperLoader -
☁️ Hỗ trợ nguồn từ bên thứ ba:
LangChain tích hợp với nhiều hệ thống lưu trữ như:
- Amazon S3 (private buckets)
- Notion, Slack
- Jupyter Notebooks (
.ipynb) - Airbyte
- Unstructured.io (xử lý tài liệu không theo cấu trúc)
📌 Tổng cộng: LangChain hỗ trợ hơn 120 loại document loaders khác nhau.
-
Text Splitters
Vì sao cần tách văn bản?h3
Trong các ứng dụng như RAG (Retrieval Augmented Generation), mô hình không thể xử lý nguyên tài liệu dài do giới hạn context window, nên cần:
- Tách tài liệu thành các đoạn nhỏ (chunks)
- Giúp mô hình xử lý, truy vấn và trả lời chính xác hơn
- Quản lý tốt hơn về hiệu suất và chi phí
⚙️ Cách hoạt động:h3
LangChain hỗ trợ nhiều chiến lược tách văn bản với logic được tối ưu cho các loại tài liệu như: HTML, Markdown, code…
- Có thể tách theo:
- Câu
- Đoạn
- Từ
- Ký tự đặc biệt (tùy chỉnh)
🔧 Các kỹ thuật tách văn bản phổ biếnh2
1. CharacterTextSplitterh3
- Tách văn bản bằng cách sử dụng một ký tự ngăn cách (separator) cố định như dấu chấm
".", dấu xuống dòng"\n",… - Sau đó kiểm tra xem đoạn tách có đạt điều kiện
chunk_sizevàchunk_overlapkhông.
from langchain_text_splitters import CharacterTextSplittersplitter = CharacterTextSplitter(separator='.',chunk_size=100,chunk_overlap=10)chunks = splitter.split_text(text)✅ Đơn giản, dễ dùng
⚠️ Không luôn đảm bảo tách đúng kích thước mong muốn, đặc biệt với văn bản phức tạp
2. RecursiveCharacterTextSplitterh3
- Tách bằng danh sách các dấu ngắt phân cấp, thử từng cách cho đến khi phù hợp với
chunk_size
from langchain_text_splitters import RecursiveCharacterTextSplittersplitter = RecursiveCharacterTextSplitter(chunk_size=100,chunk_overlap=10,separators=["\n\n", "\n", " ", ""])chunks = splitter.split_text(text)🔁 Chiến lược “thử từ dễ đến khó”:
- Tách theo đoạn
\n\n - Tách theo câu
\n - Tách theo từ
" " - Cuối cùng là ký tự
""
✅ Giữ ngữ cảnh tốt hơn
✅ Tách linh hoạt theo cấu trúc nội dung
⚠️ Một số đoạn có thể quá ngắn → cần cân nhắc thêm
🧠 Chunk Overlap là gì?h3
Là phần nội dung được lặp lại giữa hai đoạn liên tiếp.
→ Giúp mô hình giữ được ngữ cảnh xuyên suốt đoạn tách.
chunk_size = 100chunk_overlap = 20📌 Nếu bạn thấy mô hình trả lời bị “lạc đề” hoặc mất ngữ cảnh, thử tăng chunk_overlap!
-
Text embedding
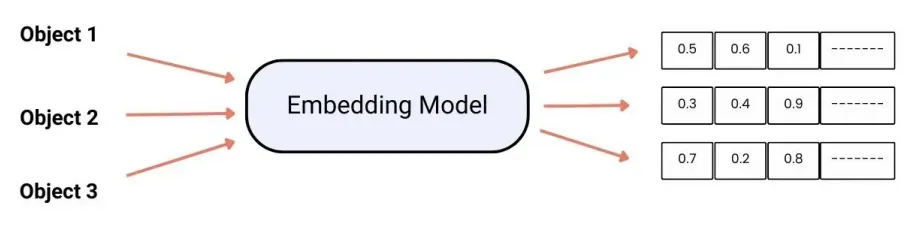
Text embedding là quá trình chuyển đổi văn bản thành các vector số có ý nghĩa ngữ nghĩa. Trong LangChain, embedding là bước trung tâm trong hệ thống Retrieval-Augmented Generation (RAG), giúp mô hình truy xuất thông tin liên quan từ cơ sở dữ liệu để tạo phản hồi chính xác hơn.
⚙️ Cách hoạt động trong LangChain
- Tạo embedding: Sử dụng các mô hình như OpenAI, Cohere, Hugging Face để chuyển đổi văn bản thành vector.
- Lưu trữ vector: Lưu các vector này vào cơ sở dữ liệu vector như FAISS, Chroma, Pinecone để phục vụ truy vấn sau này.
- Truy xuất thông tin: Khi có truy vấn, chuyển đổi truy vấn thành vector và tìm kiếm các vector tương tự trong cơ sở dữ liệu.
Các nhà cung cấp embedding được hỗ trợ
LangChain tích hợp với nhiều nhà cung cấp embedding, bao gồm:
- OpenAI, Cohere, Hugging Face, Google, AWS, MistralAI….
Xem chi tiết tại : https://python.langchain.com/docs/integrations/text_embedding/
📌 Lưu ý khi sử dụng
- Phân biệt giữa embedding query và document: Một số nhà cung cấp có phương pháp embedding khác nhau cho truy vấn và tài liệu.
- Chọn mô hình phù hợp: Tùy vào trường hợp sử dụng, chọn mô hình embedding phù hợp để đạt hiệu quả tốt nhất.
- Tối ưu hóa hiệu suất: Sử dụng các kỹ thuật như batching và caching để cải thiện hiệu suất khi xử lý lượng lớn văn bản.
-
Vector database

Chọn vector database trong LangChainh3
LangChain cung cấp nhiều lựa chọn vector database khác nhau, từ các giải pháp open-source cài đặt cục bộ cho đến các giải pháp proprietary được lưu trữ trên cloud. Khi lựa chọn giải pháp phù hợp, bạn cần xem xét các yếu tố sau:
Các yếu tố cần cân nhắc khi chọn vector database
- Yêu cầu tùy biến cao: Nếu bạn cần một hệ thống có tính tùy biến cao, các giải pháp open-source sẽ là sự lựa chọn phù hợp, vì bạn có thể dễ dàng tùy chỉnh chúng theo nhu cầu sử dụng.
- Lưu trữ dữ liệu: Cân nhắc xem dữ liệu của bạn có thể được lưu trữ trên các máy chủ bên ngoài (third-party servers) hay không. Không phải tất cả các trường hợp đều cho phép điều này.
- Dung lượng lưu trữ và độ trễ truy vấn: Dung lượng lưu trữ và độ trễ truy vấn là những yếu tố quan trọng cần xem xét. Đôi khi một cơ sở dữ liệu nhẹ sử dụng bộ nhớ trong (in-memory database) sẽ đủ, nhưng với các yêu cầu lưu trữ lớn và truy vấn nhanh, bạn sẽ cần một giải pháp mạnh mẽ hơn.
ChromaDB: Đây là giải pháp vector database nhẹ và dễ thiết lập, rất phù hợp cho các ứng dụng yêu cầu tốc độ cao và dung lượng lưu trữ nhỏ. Trong khoá học này, chúng ta sẽ sử dụng ChromaDB vì lý do trên.
Các giải pháp khác: LangChain cung cấp hơn 50 lựa chọn vector store khác nhau, bao gồm cả các giải pháp cài đặt cục bộ như FAISS, Pinecone, hay các giải pháp cloud như Amazon Kendra, Weaviate. Bạn có thể chọn giải pháp phù hợp dựa trên yêu cầu về tính linh hoạt, tốc độ, và khả năng lưu trữ.
- FAISS: Lựa chọn phổ biến cho các ứng dụng yêu cầu tốc độ truy vấn nhanh và tính mở rộng cao.
- Pinecone: Một giải pháp cloud-hosted mạnh mẽ, hỗ trợ phân phối và tìm kiếm vector trên quy mô lớn.
- Weaviate: Cung cấp tính năng tìm kiếm ngữ nghĩa, tương thích tốt với các mô hình LLMs.
- Redis Vector Search: Giải pháp vector store tích hợp với Redis, nhanh chóng và dễ triển khai.
- Qdrant: Cung cấp khả năng tìm kiếm vector, có thể sử dụng trong các ứng dụng thời gian thực.
Tích hợp với LangChainh3
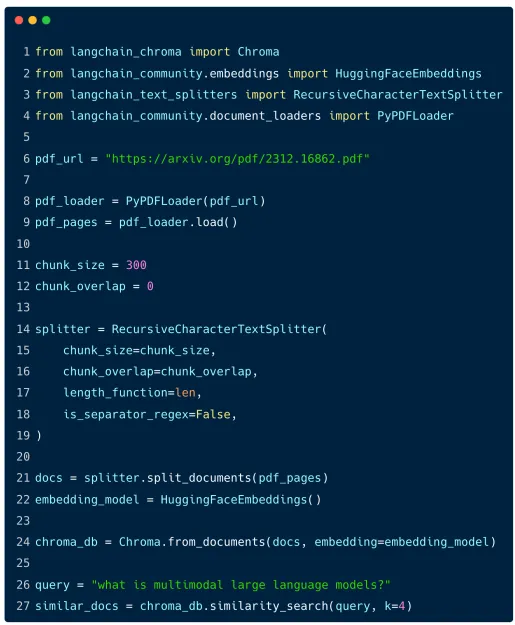

LangChain cung cấp một giao diện chuẩn cho các vector store, giúp bạn dễ dàng thay thế giữa các giải pháp mà không cần phải thay đổi quá nhiều trong mã nguồn. Dưới đây là một ví dụ về cách tích hợp ChromaDB với LangChain:
- Tạo embedding: Sử dụng mô hình embedding từ OpenAI (có thể từ hunggingfaceembedding), chúng ta có thể chuyển đổi văn bản thành các vector để lưu trữ.
- Tạo cơ sở dữ liệu Chroma: Dùng phương thức
.from_documents()trên class Chroma để tạo một database từ một tập hợp các tài liệu. Chúng ta cũng chỉ định nơi lưu trữ cơ sở dữ liệu này để có thể sử dụng lại trong tương lai. - Chuyển đổi thành retriever: Cuối cùng, sử dụng phương thức
.as_retriever()để chuyển cơ sở dữ liệu thành một retriever, có thể tìm kiếm tài liệu tương tự dựa trên truy vấn người dùng.
-
Format của docs khi splitter xong trước khi đưa vào Chroma

3.3. RAG with LangChainh2
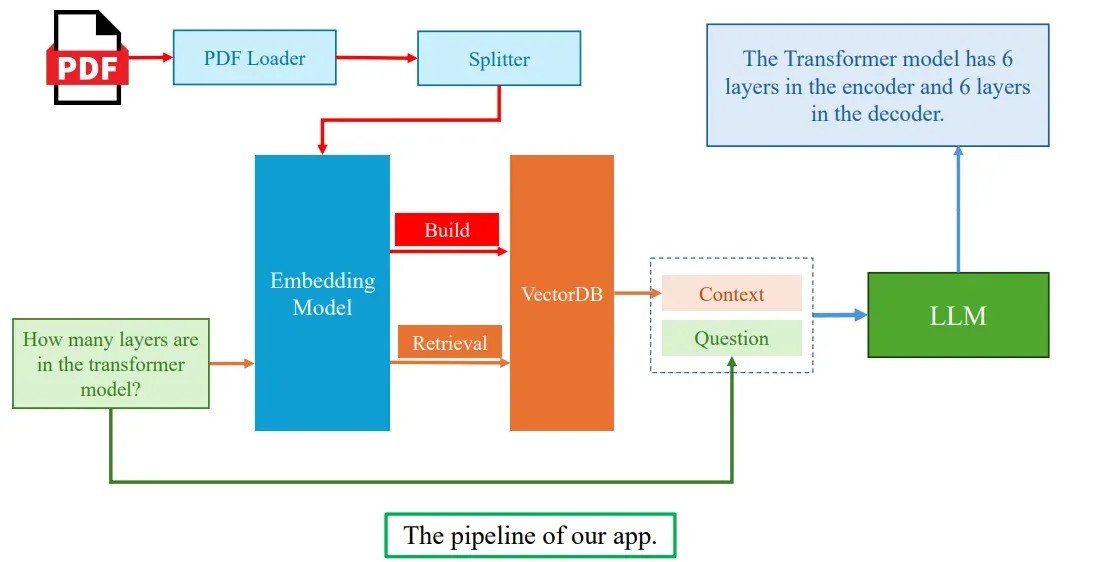
Khái niệm về vector database:
- Vector database là cơ sở dữ liệu được tối ưu để lưu trữ và truy vấn các vector. Các vector này được tạo ra bằng cách sử dụng các mô hình embedding, giúp nắm bắt ý nghĩa ngữ nghĩa của các văn bản.
- Mỗi văn bản được chuyển đổi thành một vector, mà mô hình có thể so sánh để tìm ra các văn bản tương tự, từ đó cung cấp ngữ cảnh giúp trả lời câu hỏi chính xác hơn.
- LangChain hỗ trợ việc sử dụng các vector database để lưu trữ và truy vấn các tài liệu đã được chia nhỏ (chunked).
Quy trình sử dụng vector databases trong LangChain:
- Tải và phân tích tài liệu: Dữ liệu được tải lên từ các nguồn như PDF, CSV, HTML và sau đó chia nhỏ (split) thành các phần nhỏ (chunks).
- Embedding và lưu trữ: Các tài liệu này được embedding, chuyển đổi thành các vector, và lưu trữ vào một vector database.
- Tìm kiếm và truy vấn: Khi có một câu hỏi từ người dùng, câu hỏi này cũng được embedding và so sánh với các vector trong cơ sở dữ liệu để tìm ra các tài liệu có ngữ cảnh phù hợp.